浣石采集器是一款领先的互联网数据采集器,集数据采集、清洗、分析、挖掘、洞察、可视化及报告生成于一体,助力用户高效精准地采集并深度分析互联网数据,生成富有洞察力的分析报告。
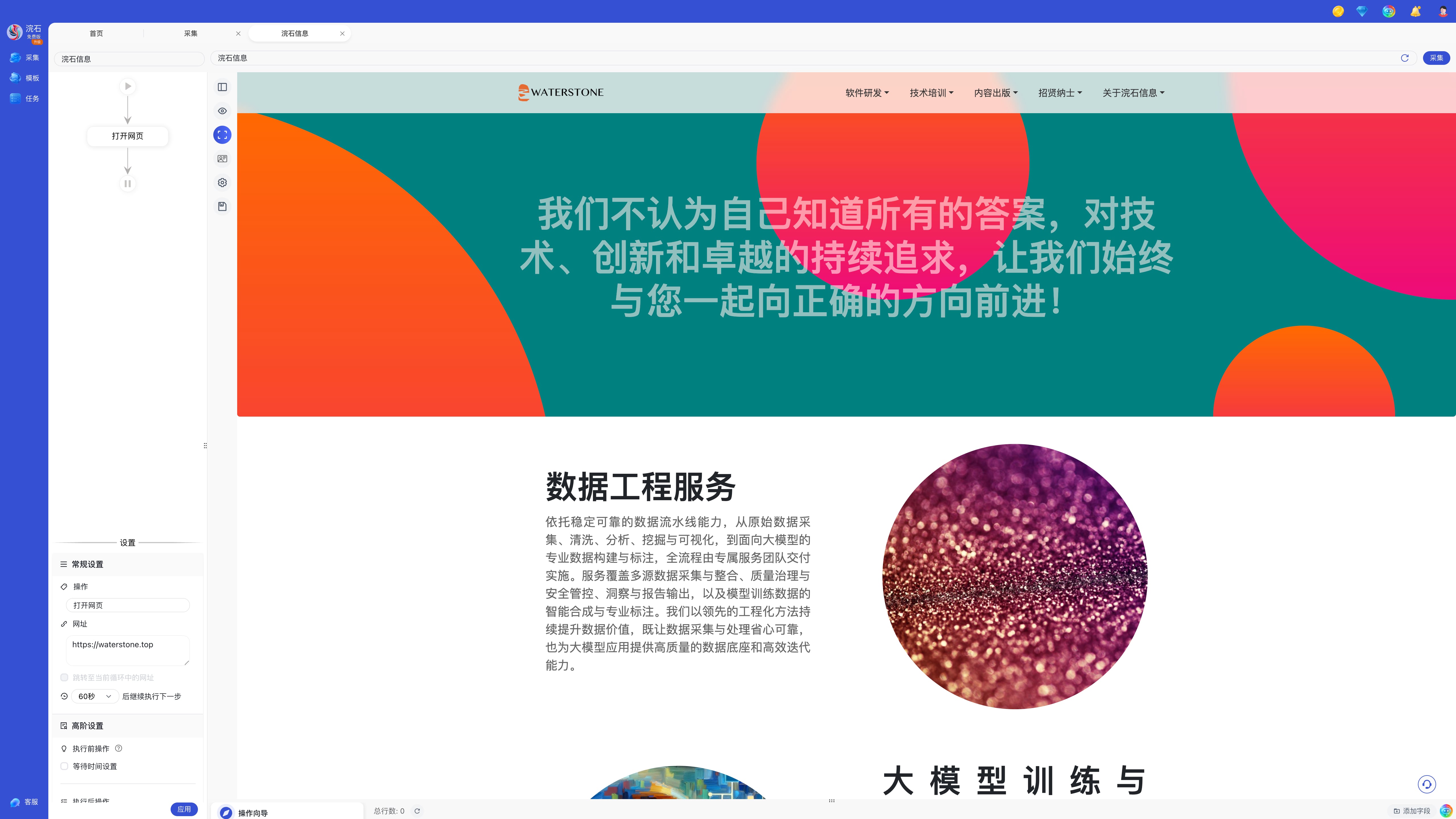
目前 Windows 用户可通过以下渠道下载安装浣石采集器:
1. Microsoft Store(微软应用商店)
- 最安全、最受信任的渠道,无需担心签名或安全提示。
- Windows 系统自带商店,您可直接在 Microsoft Store 桌面客户端或 Web 端商店页面搜索“浣石采集器”并下载安装。
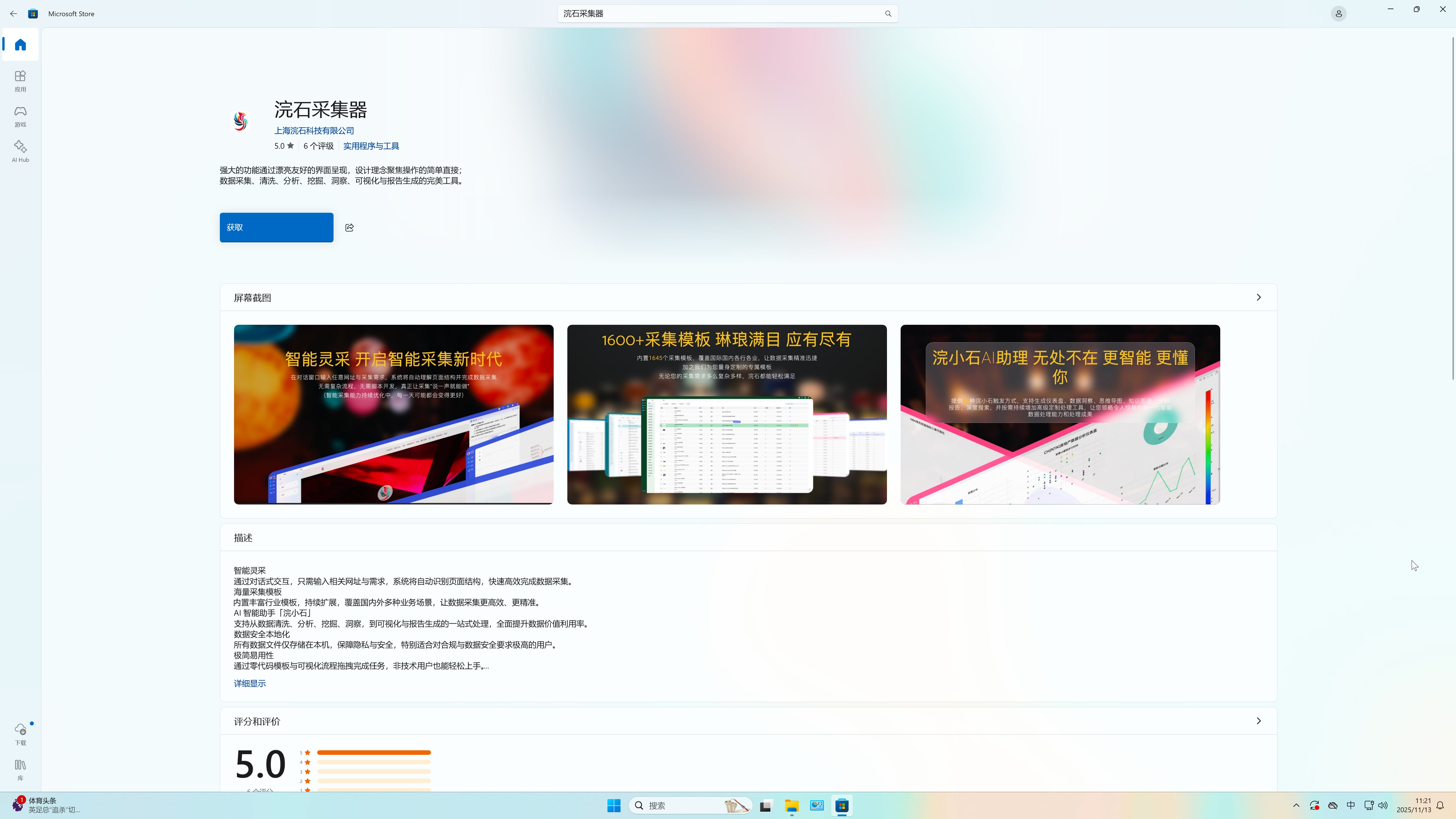
2. 华为应用市场
- 支持 Windows 桌面客户端下载。
- 提供最新版本的浣石采集器。
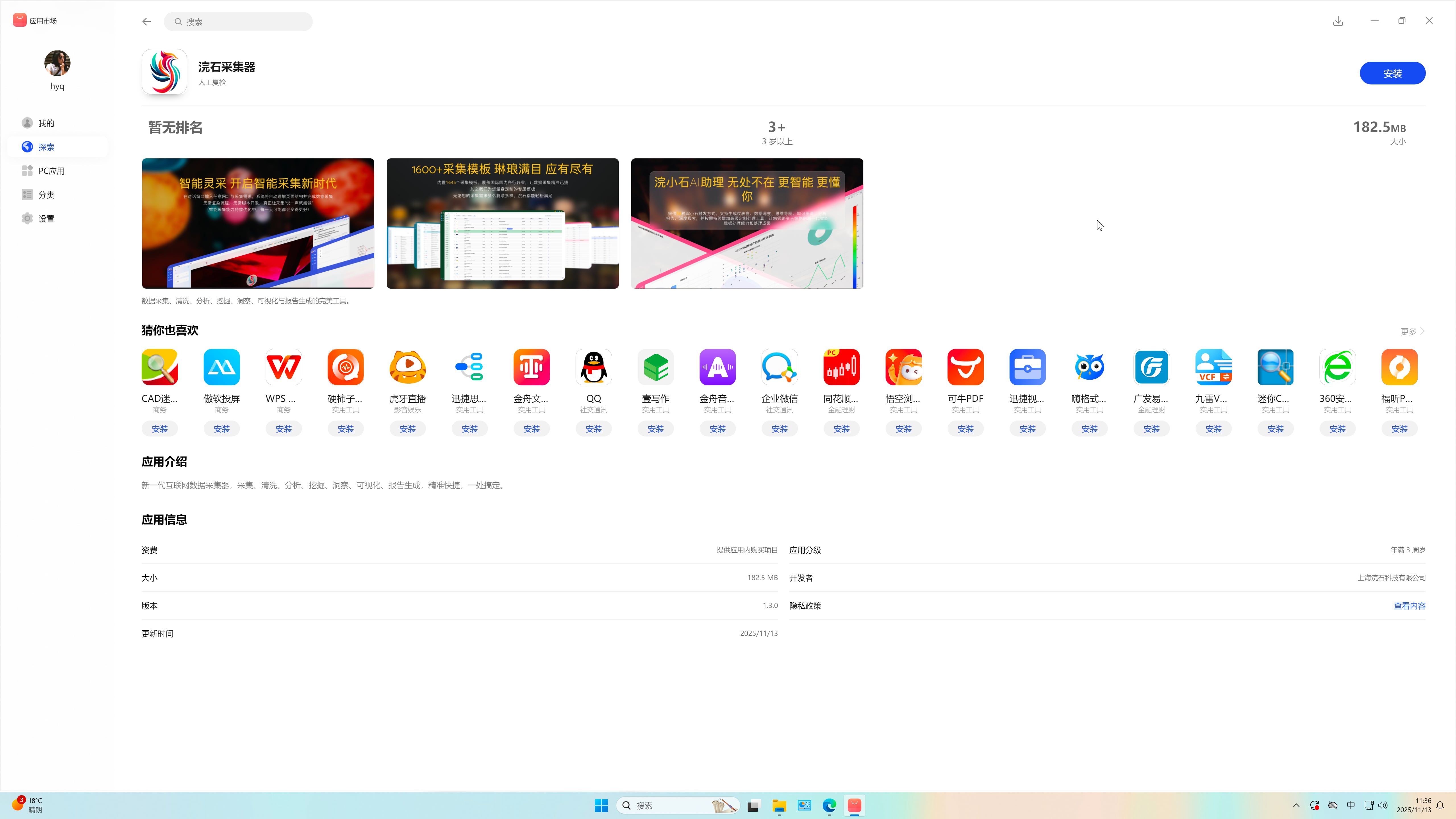
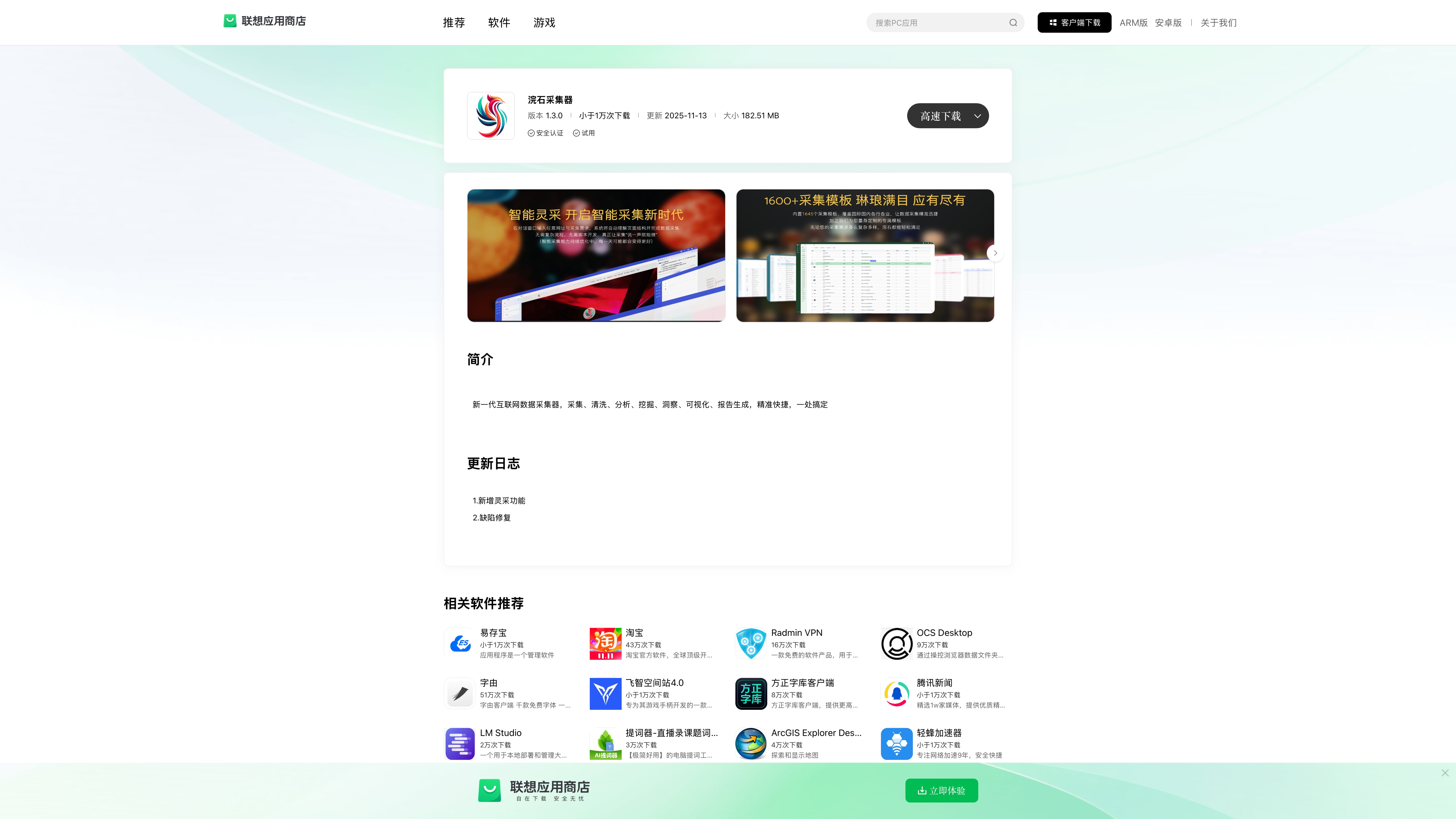
5. 鸿蒙应用商店
- 支持 HarmonyOS 桌面端客户端。
首次使用,请完成注册并登录账号。支持手机号、QQ、微信等多种方式。

注册后将自动跳转至首页。
您可以在搜索框中输入您感兴趣的数据后,点击搜索图标或按回车键,下拉框会展示匹配的搜索结果。点击列表项可在浏览器中浏览对应网址,此外,您还可以进行自定义采集、网页总结、网页生成思维导图、知识图谱和深度搜索。
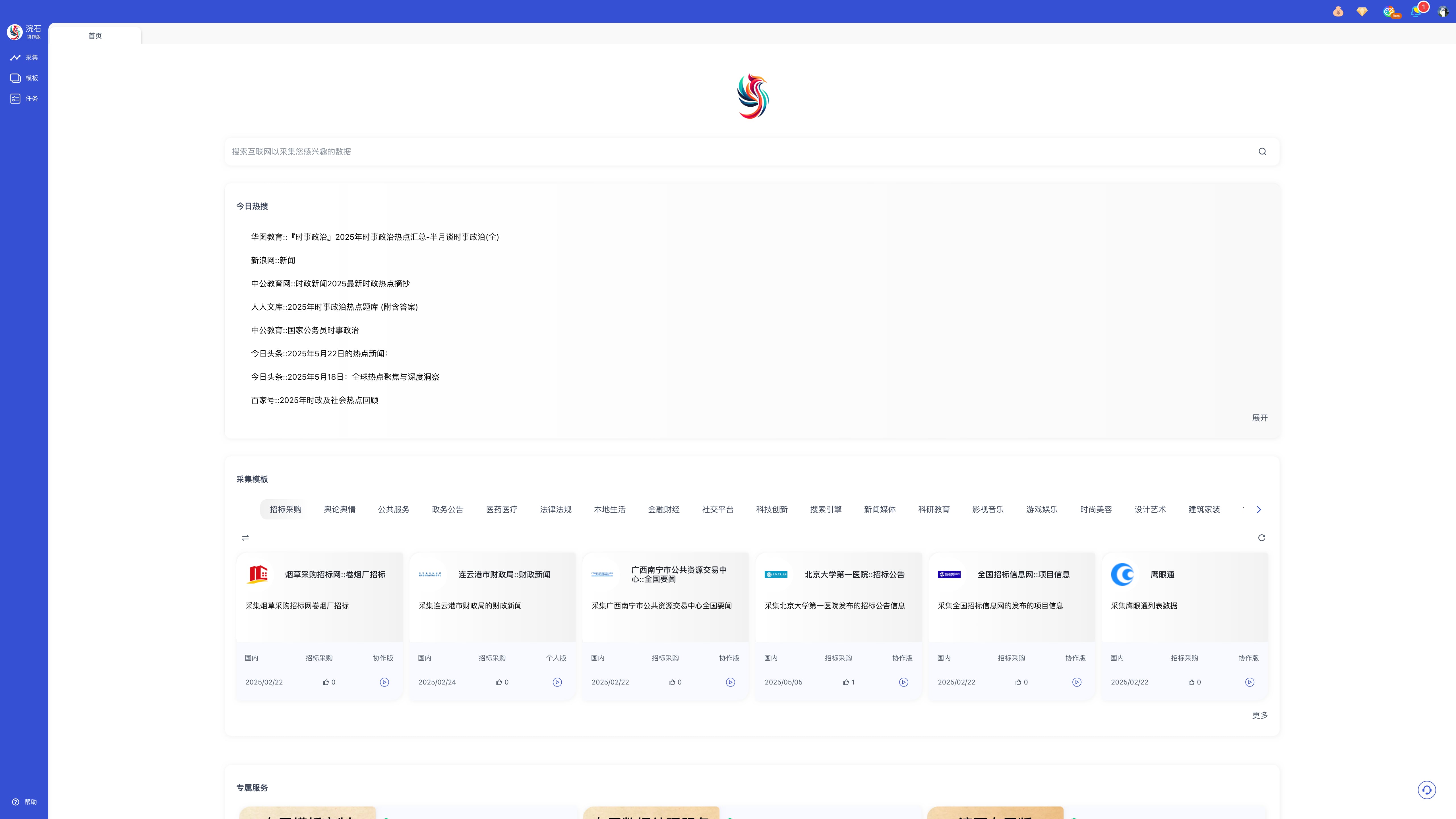
首页包含三个模块:
a. 今日热搜:展示每日热门内容,支持一键采集、网页总结、生成思维导图、知识图谱及深度搜索。
b. 采集模板:精选热门模板,可直接点击「开始采集」或查看更多模板。
c. 专属定制服务:可提交个性化数据处理需求,我们的顾问将与您联系,量身定制解决方案。
支持元素智能识别网页内容和手动点选,操作向导、流程图交互友好直观,数据预览一目了然、任务设置全面灵活,包含了多样的强化采集服务和3种加速机制。
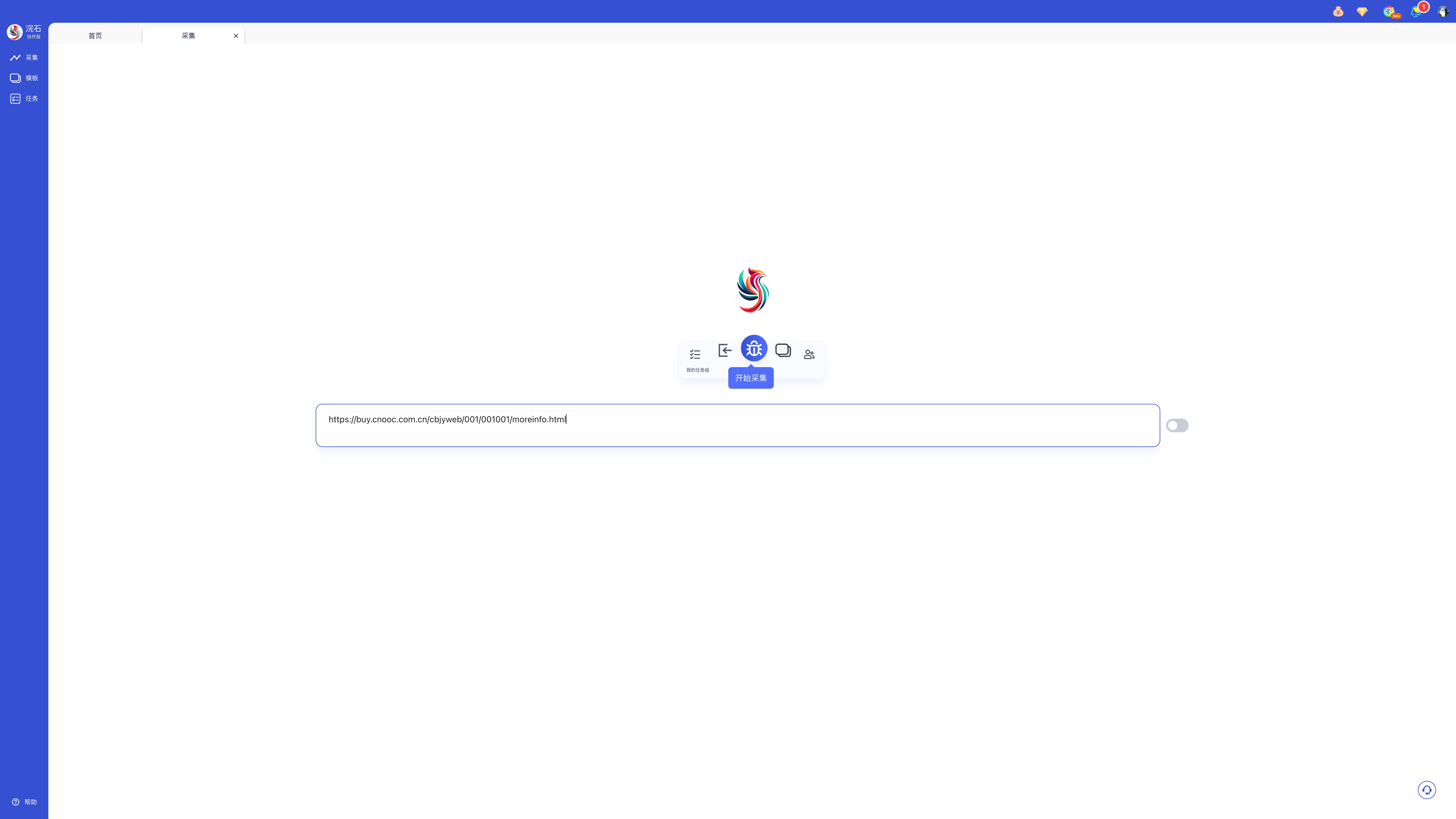
步骤一:输入目标网址,示例网址为https://nba.hupu.com/stats/players,点击「开始采集」或按回车键进入自定义采集页。
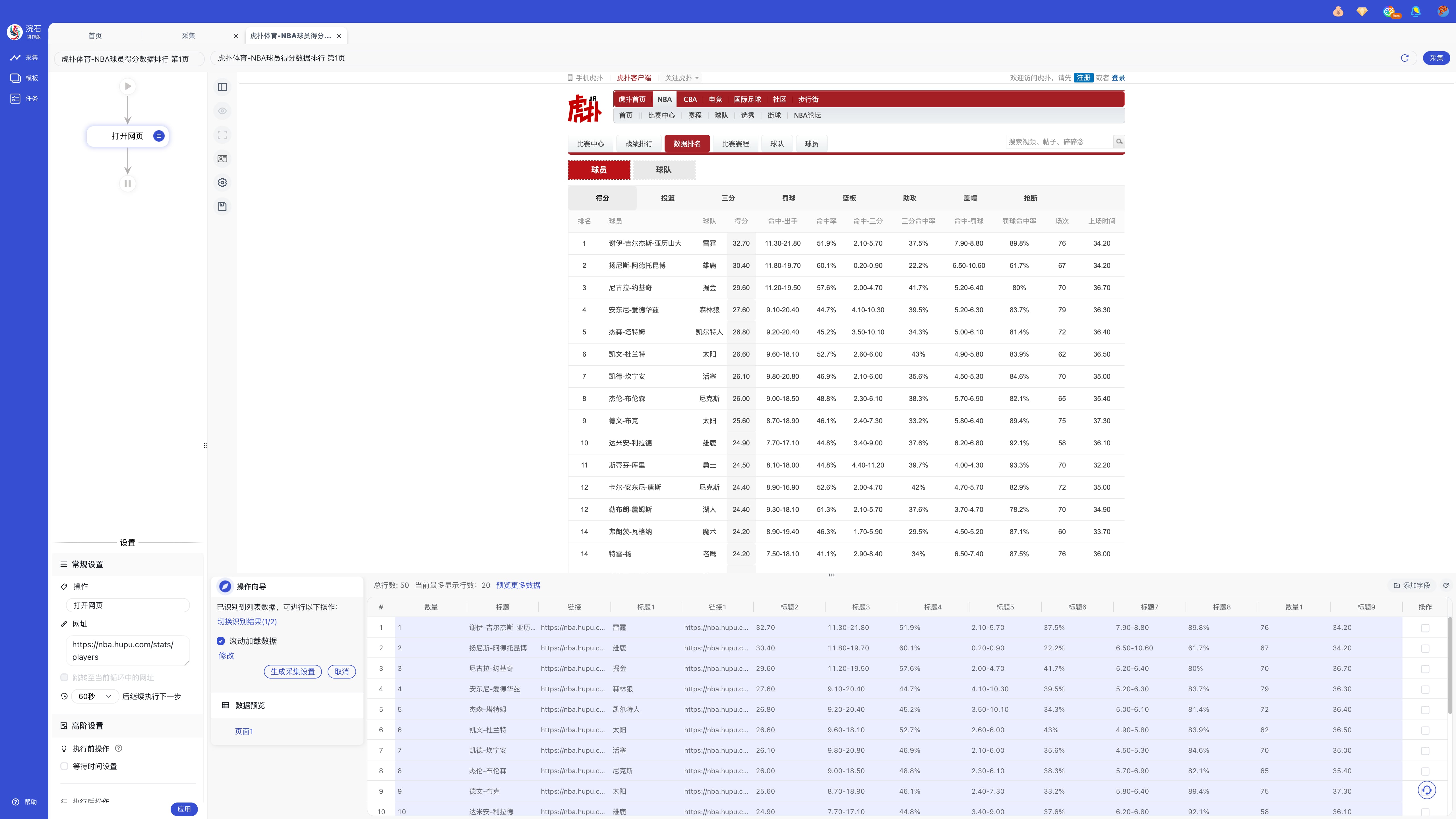
您可以点击侧边栏或下方操作向导的「元素智能识别」按钮,智能识别网页中的结构化数据。
提醒:识别过程中,随时可「取消自动识别」或「不再自动识别」。
步骤二:元素智能识别成功后,如识别到多组数据,可自行「切换识别结果」。
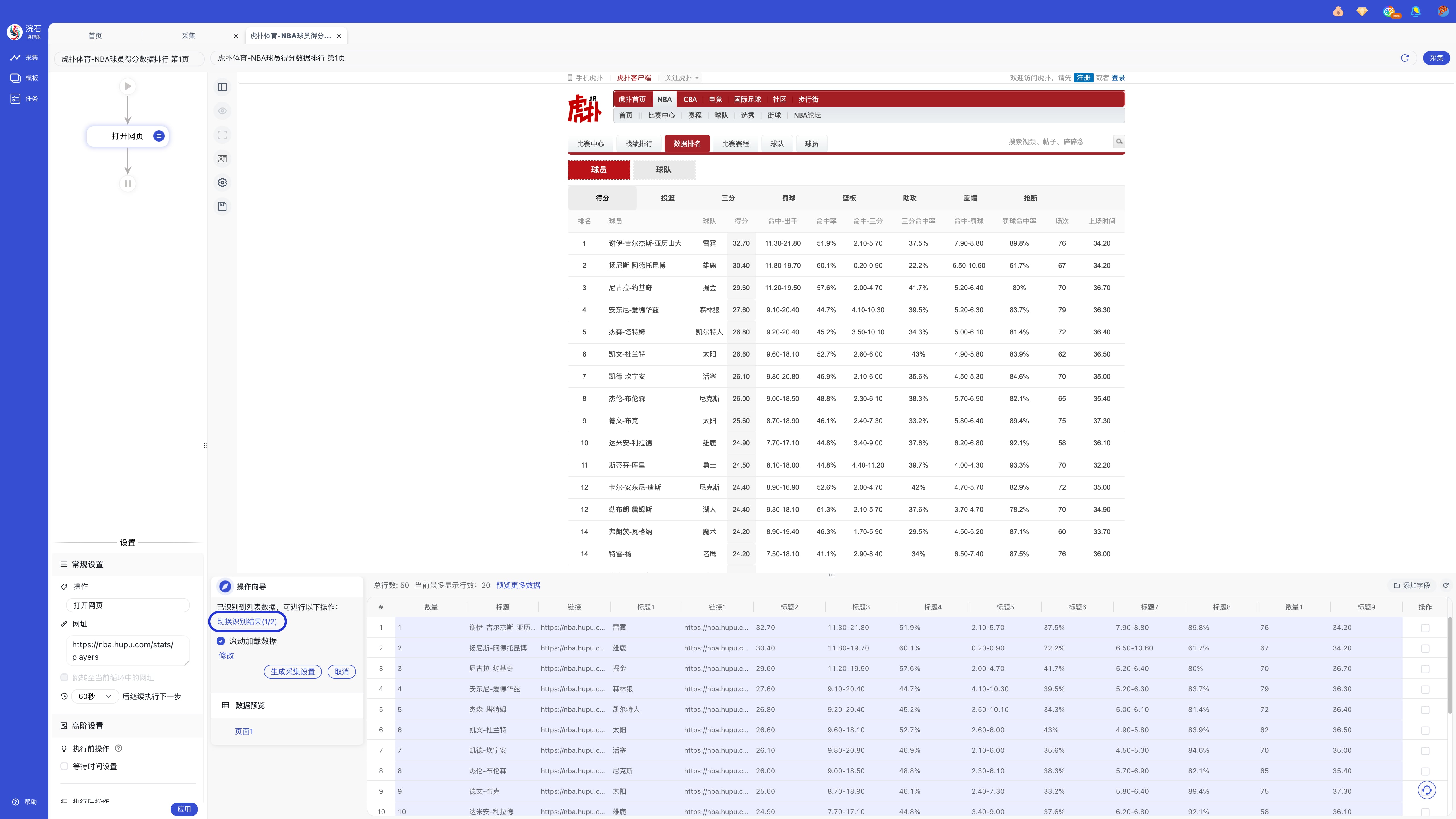
步骤三:点击「生成采集设置」生成对应的采集流程。
步骤四:点击「生成采集任务」或右上角「采集」按钮开始采集网页数据。
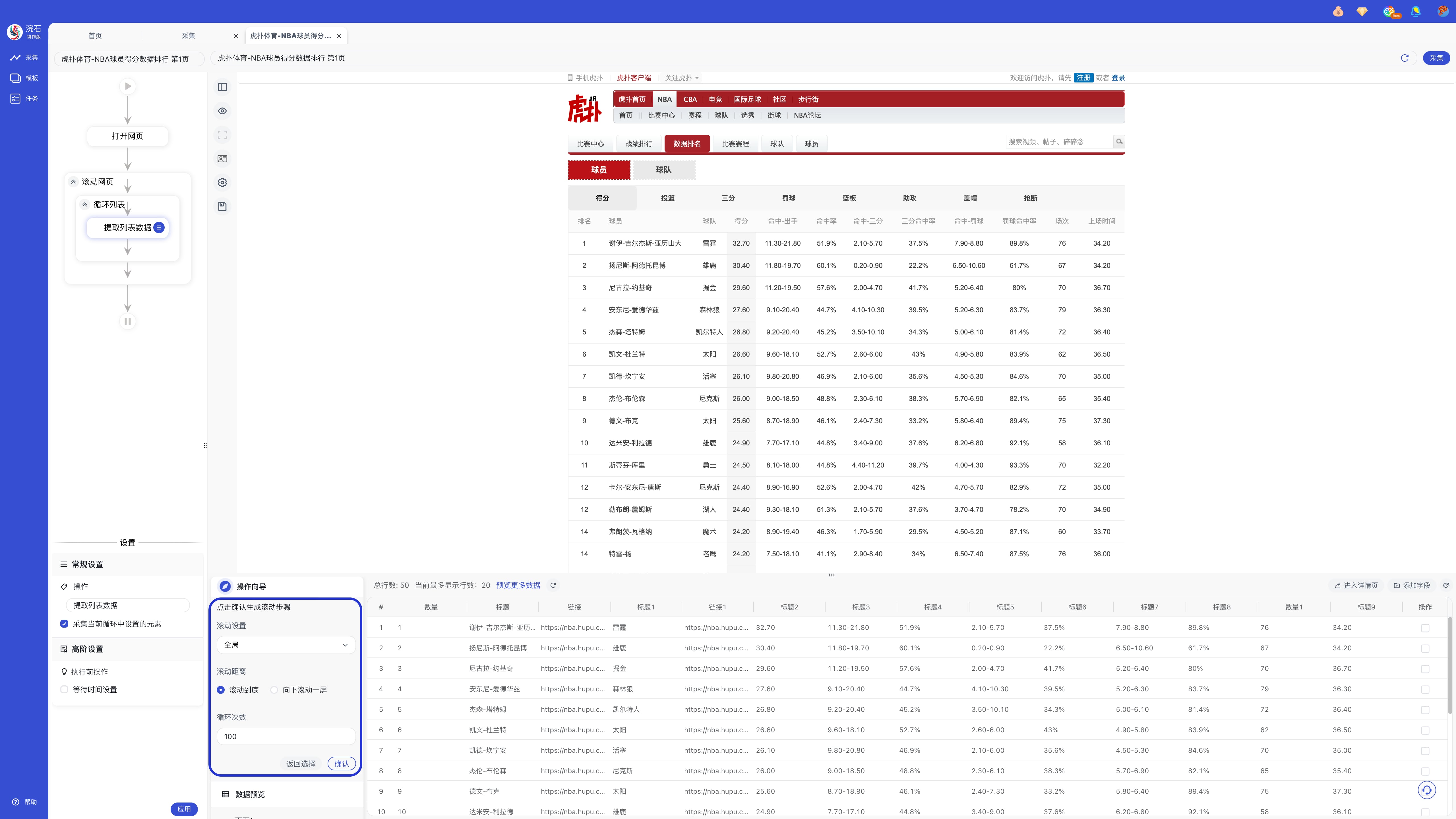
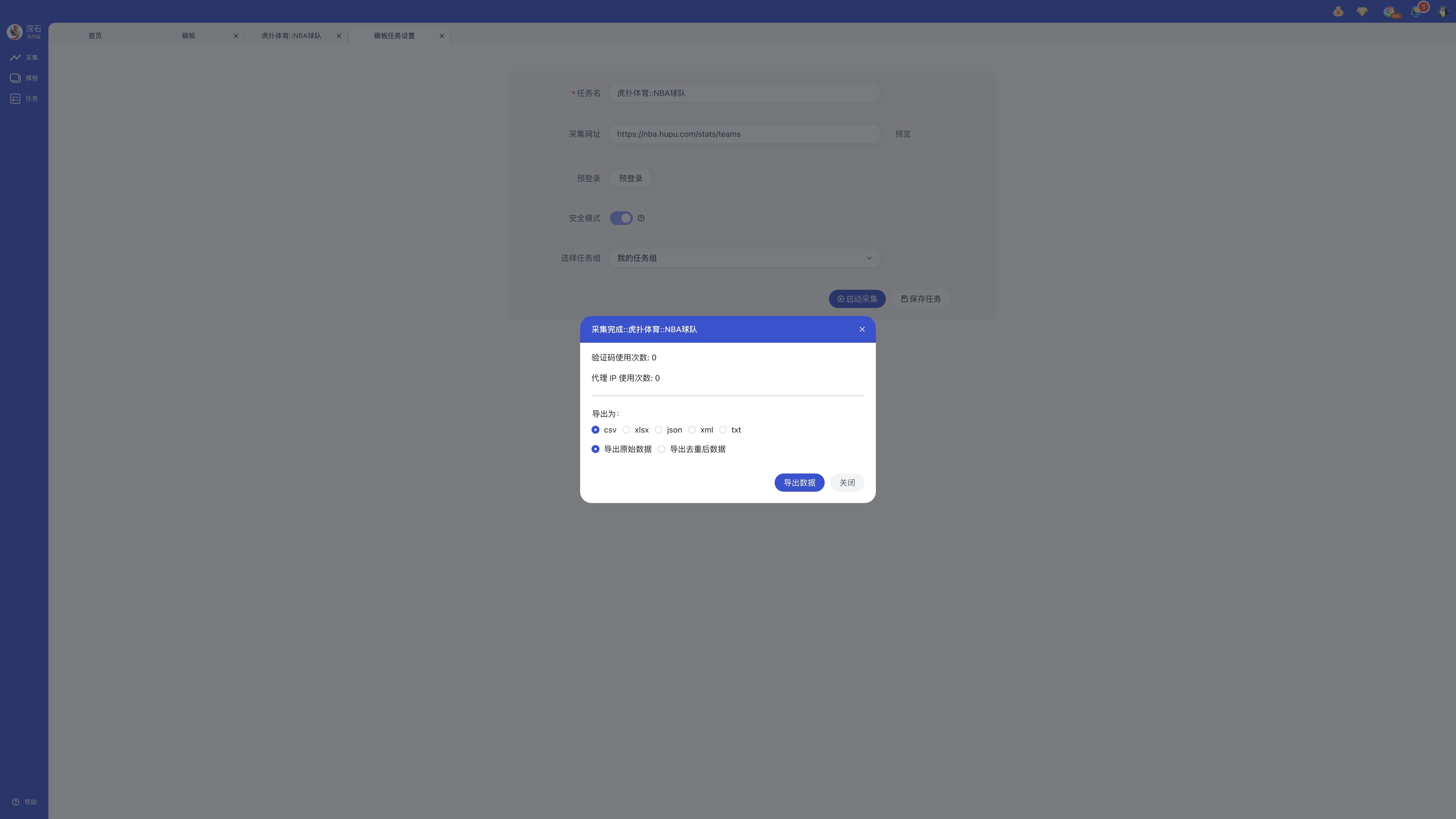
步骤五:采集完成后,可「导出数据」或「关闭」。
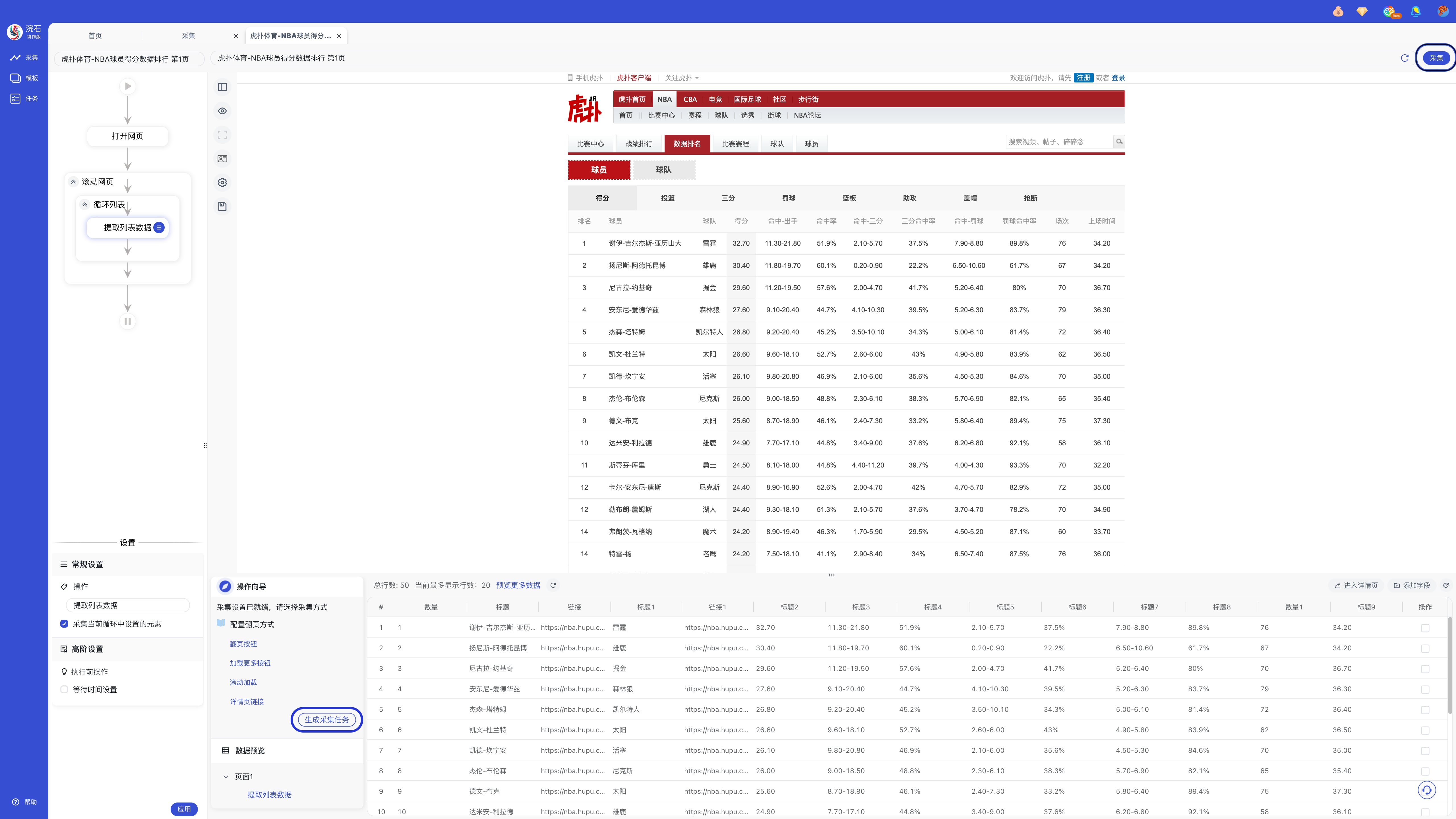
特别提醒:采集完成的数据会保存至「任务」模块,随时可再次查看或导出。
示例网址:https://ecp.cgnpc.com.cn/zbgg.html
进入采集页后,左侧显示流程图与设置,底部是操作向导与数据预览,目前没有配置规则,所以数据为空。
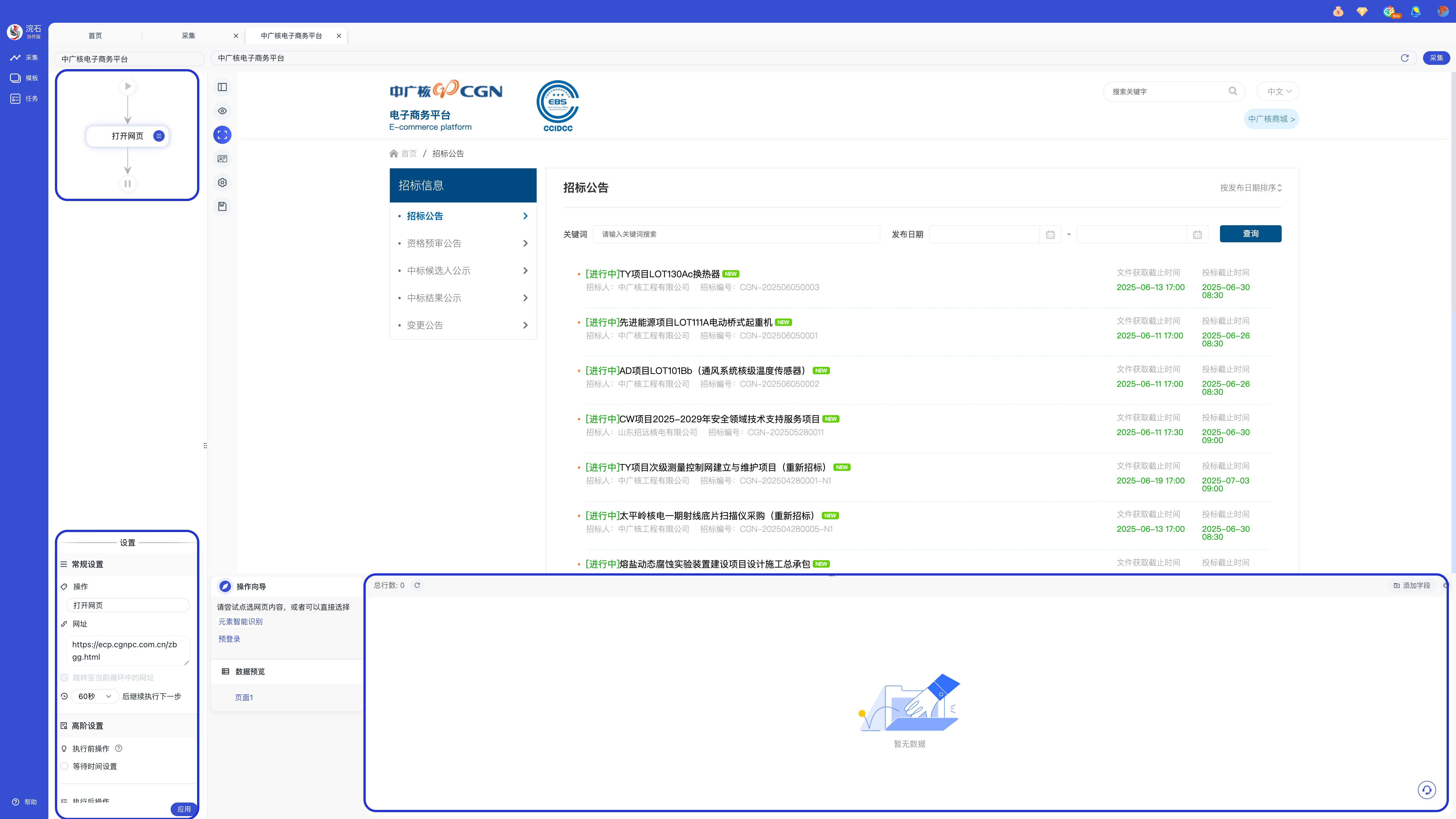
通过点选网页上的元素,网页内被选中的数据会出现蓝色高亮提示,同时操作向导也随动变化,此时可进行「提取数据」、「鼠标操作」或「提取全部相似元素」。
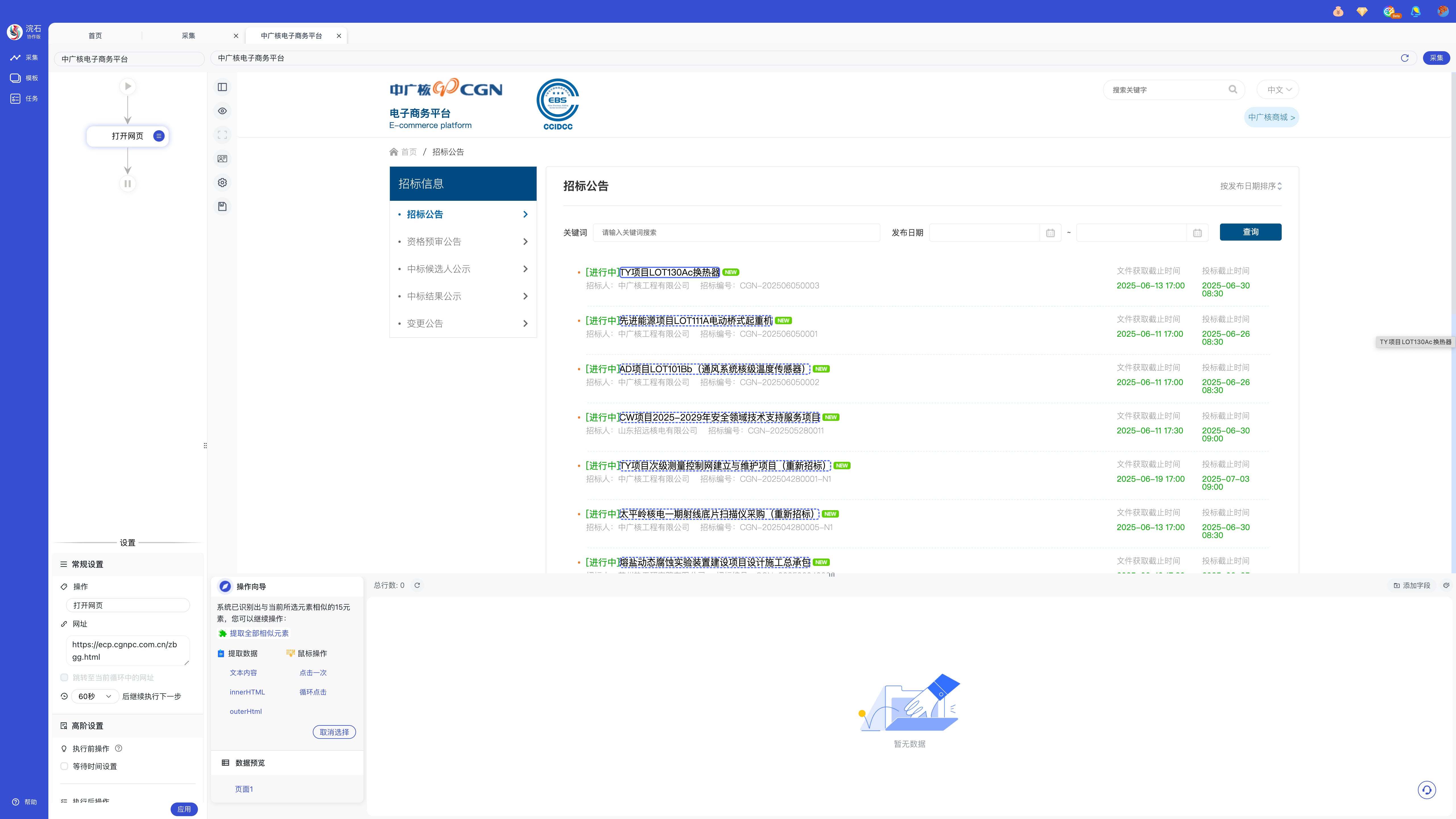
选择「提取全部相似元素」并提取数据后可看见底部数据预览部分出现数据,此时可根据网页配置翻页方式,实现多页数据采集。
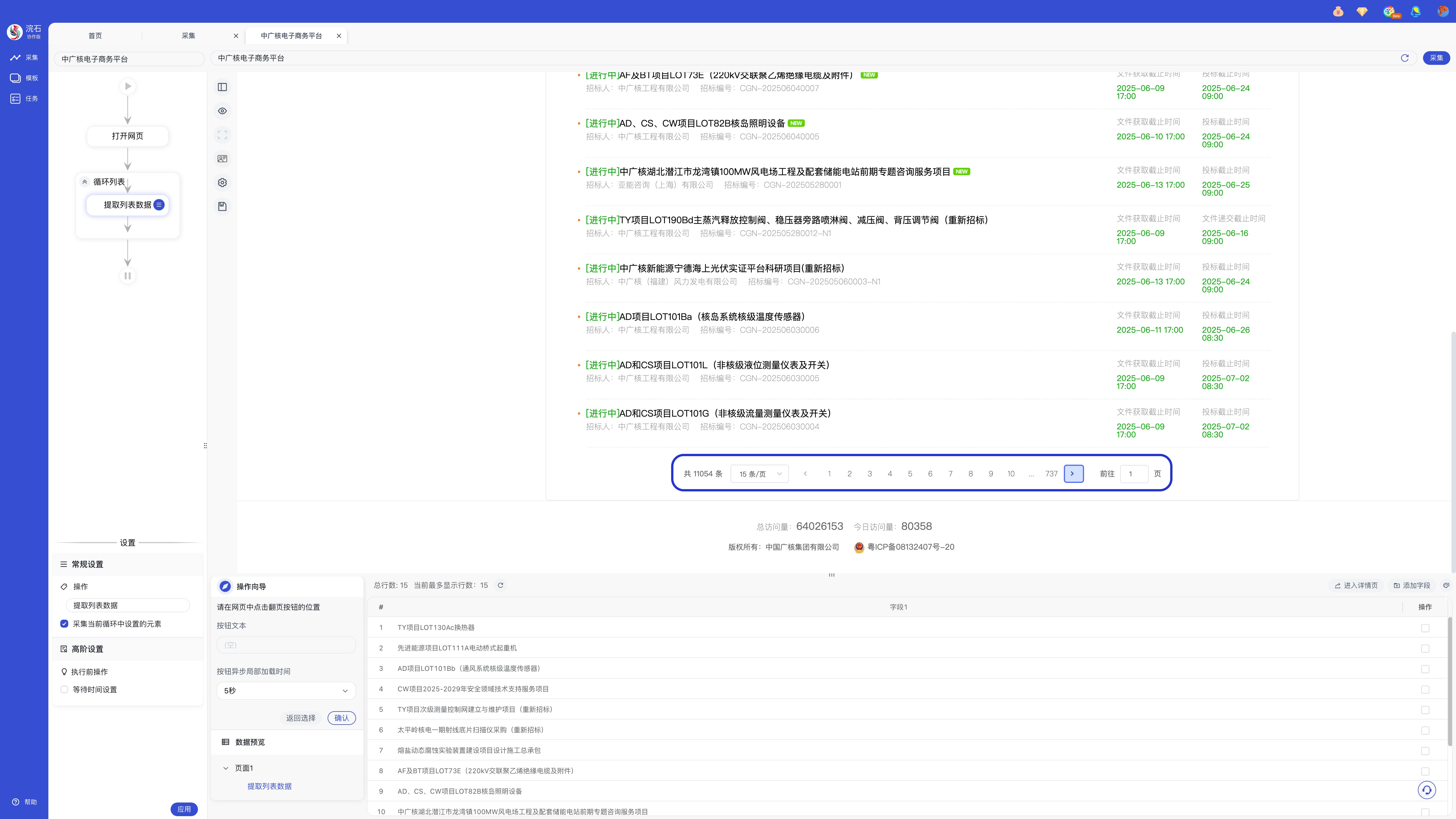
设置完所有步骤后,点击「生成采集任务」或点击右上角「采集」开始采集网页数据。采集完成后,可选择「导出数据」或「关闭」
在点选网页元素的同时,左边的流程图与设置也会发生对应的变化,将鼠标移动到流程图两个图元中间的位置,会出现添加按钮。点击按钮,可快速添加流程步骤。
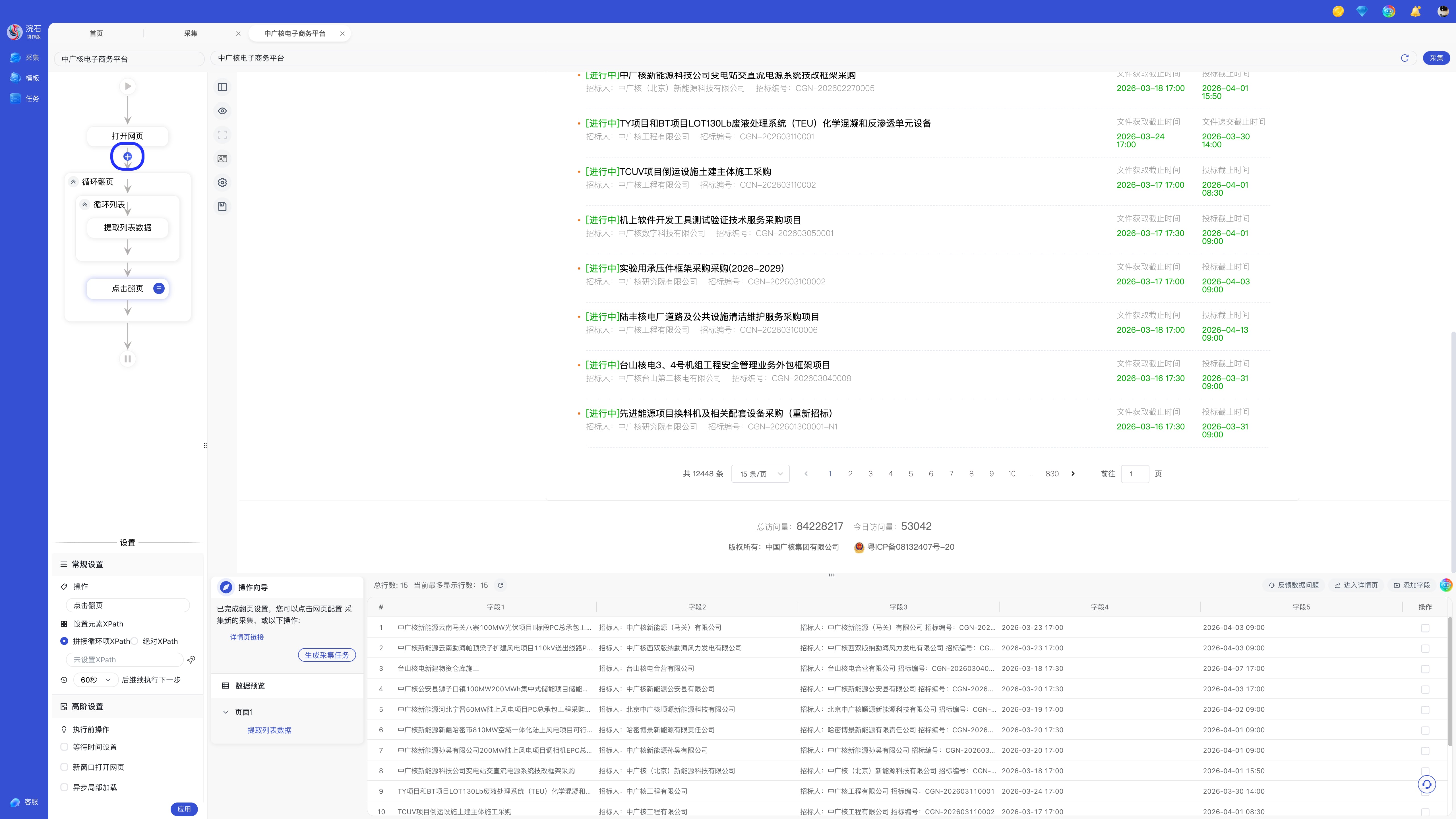
点击「流程图」的每个图元,会在下方呈现对应的设置页面,选择需要执行的操作后,点击后下角「应用」保存。
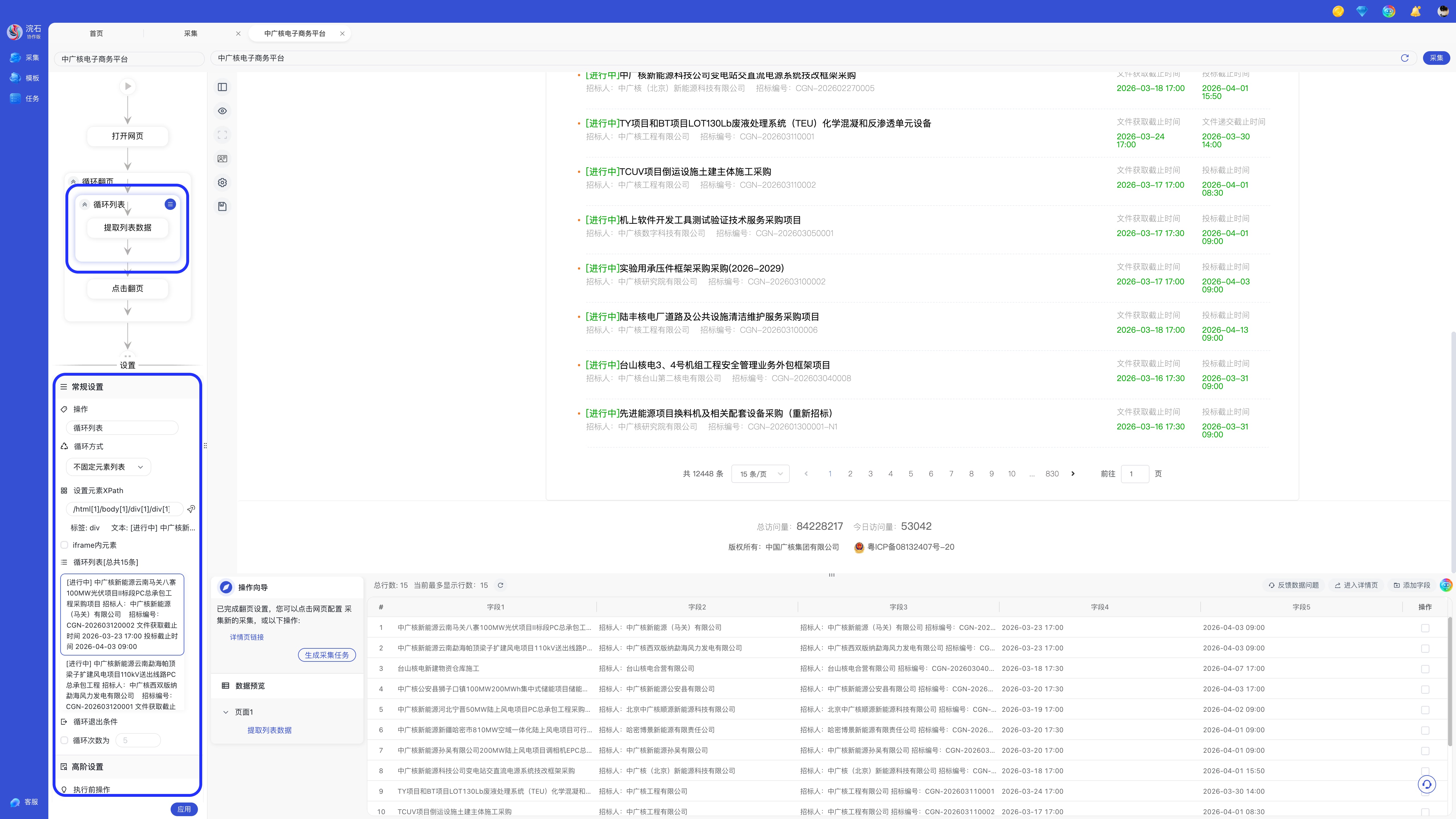
自定义采集侧边栏支持说明:
a. 折叠/展开流程图
b. 浏览模式:点击左边栏「浏览模式」可以在像浏览器中一样正常点击网页。
c. 元素智能识别:智能识别网页中的结构化数据。
d. 预登录:点击左边栏「预登录」可登录网站,登录完成后点击「关闭并提交Cookies」可保存您的登录信息。
e. 设置:点击左边栏「设置」可对该自定义采集任务设置相关操作。
f. 保存:保存采集任务,可到「任务」模块查看。
浣石采集器提供了1603个模板,涵盖国内外主流网站的多种数据,此外,采集模板还在不断的增加。
模板类型覆盖(多行业 25+ 类):招标投标、电子商务、舆情舆论、公共服务、政务公告、医药医疗、法律法规、本地生活、金融财经、社交平台、科技创新、搜索引擎、新闻媒体、科研教育、影视音乐、游戏娱乐、时尚美容、建筑家装、古董美术、出版社、图书馆、竞技体育、设计艺术、会议活动、农林牧渔、其他。
典型模板示例(部分):国家电网 ECP 电工招标公告、淘宝网:商品列表页采集、知微事见:事件列表、中华网:要闻、小红书:关键词笔记采集、深圳市人民政府:政策法规。
可按您的喜好调整卡片/表格视图显示。
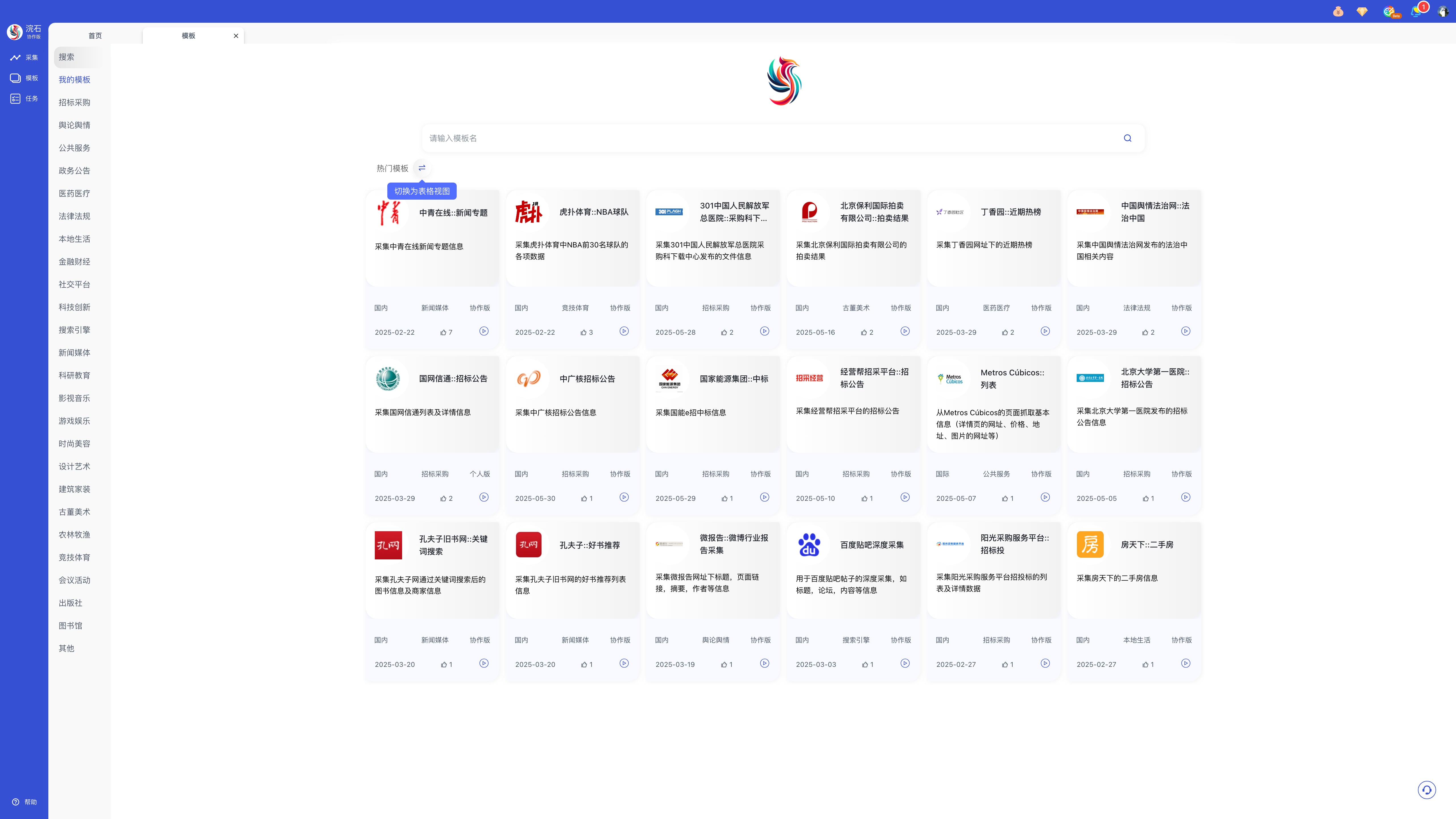
下面是模板采集的示例:
步骤一:在搜索框输入需要的网站名称,选择合适模板。
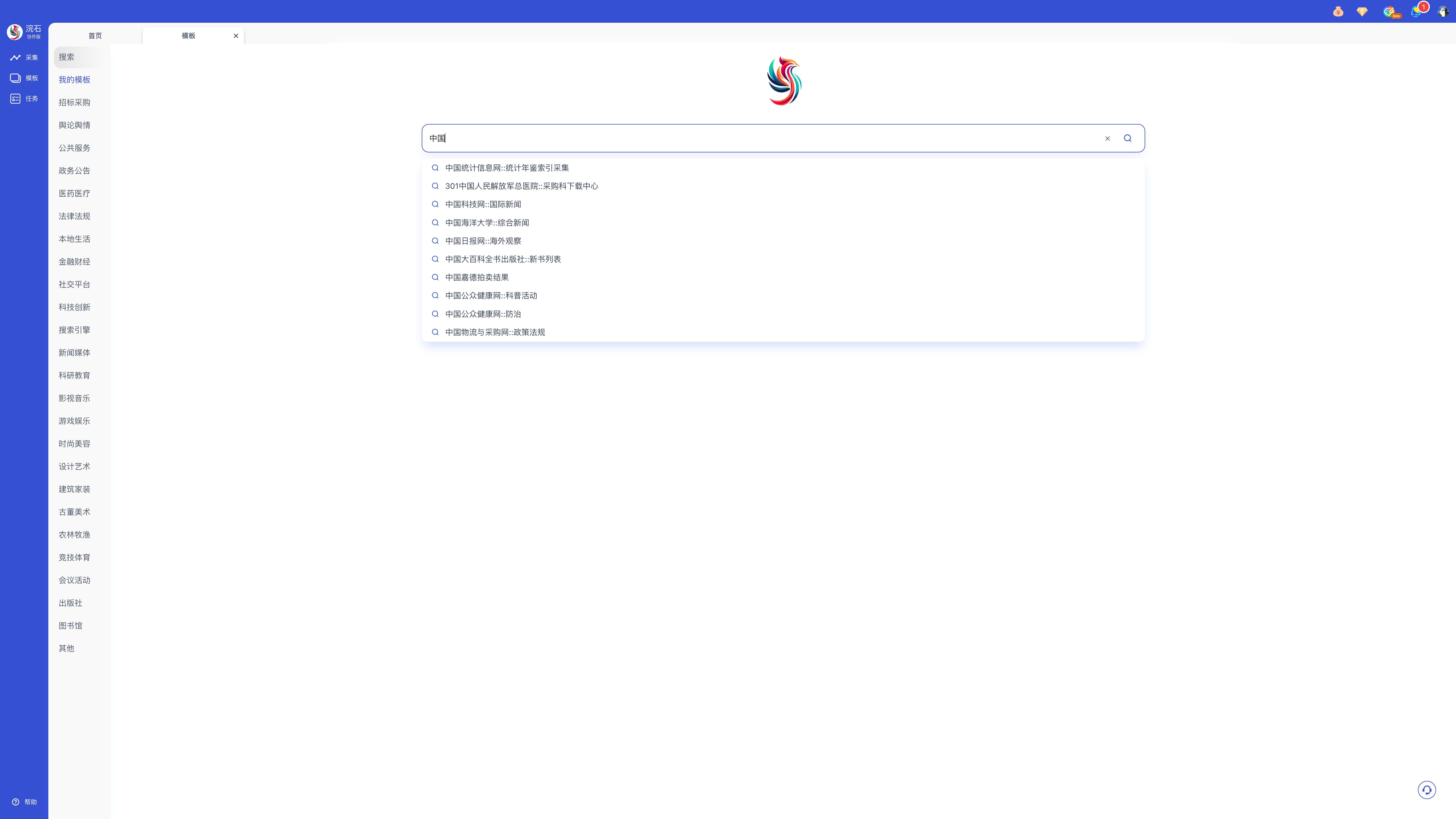
步骤二:点击「开始采集」进入模板详情页配置参数,按所需设置采集页数,关键词等。如果您选择了国际版模板,需要确保您可以正常访问网址。
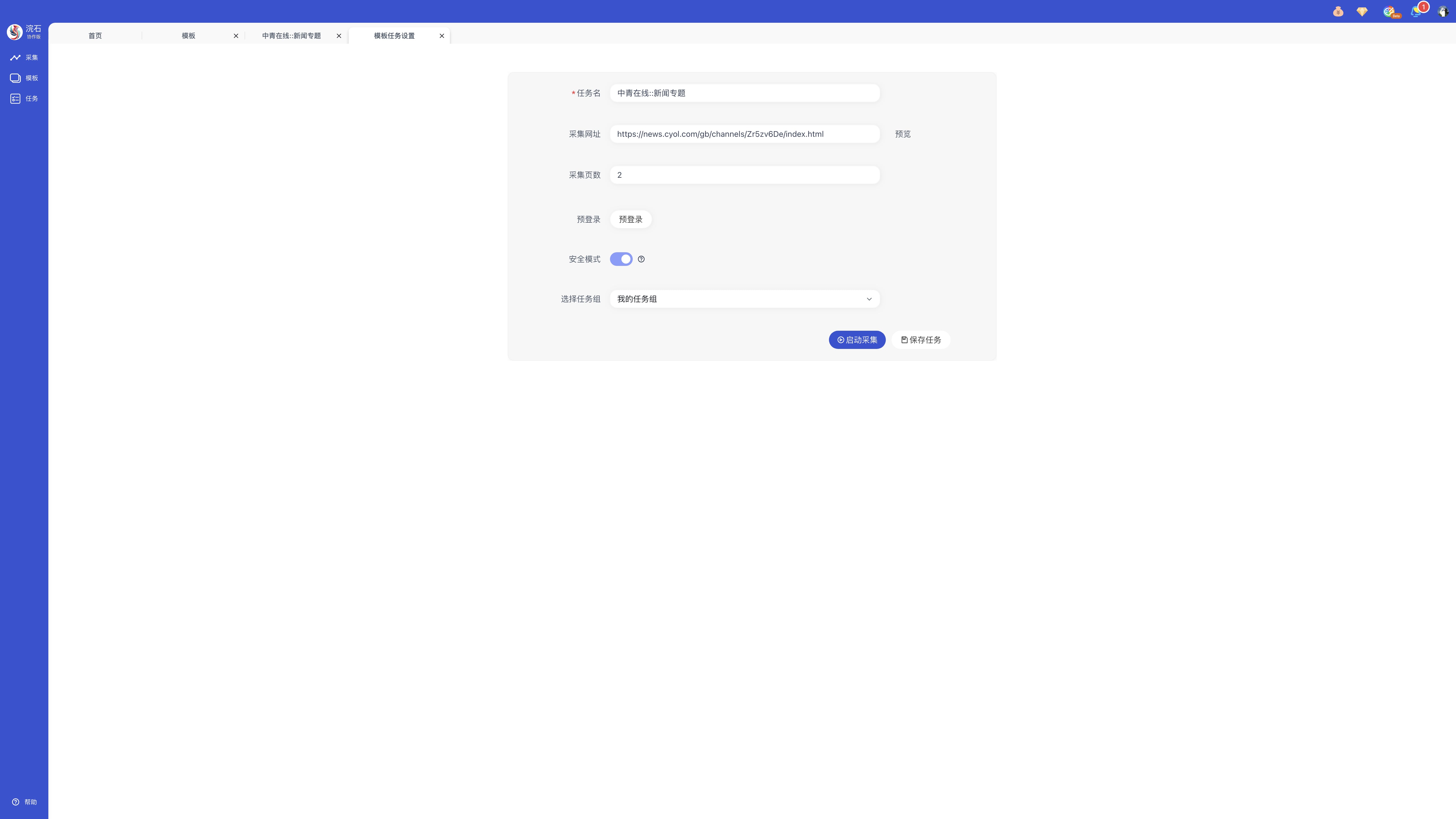
特别提醒:部分网站需要预登录,采集模板前可在模板详情页阅读使用说明和注意事项。
步骤三:点击「普通采集」/「加速采集」启动任务。
提示:「加速采集」适用于文本循环、网址循环或固定元素循环的任务。
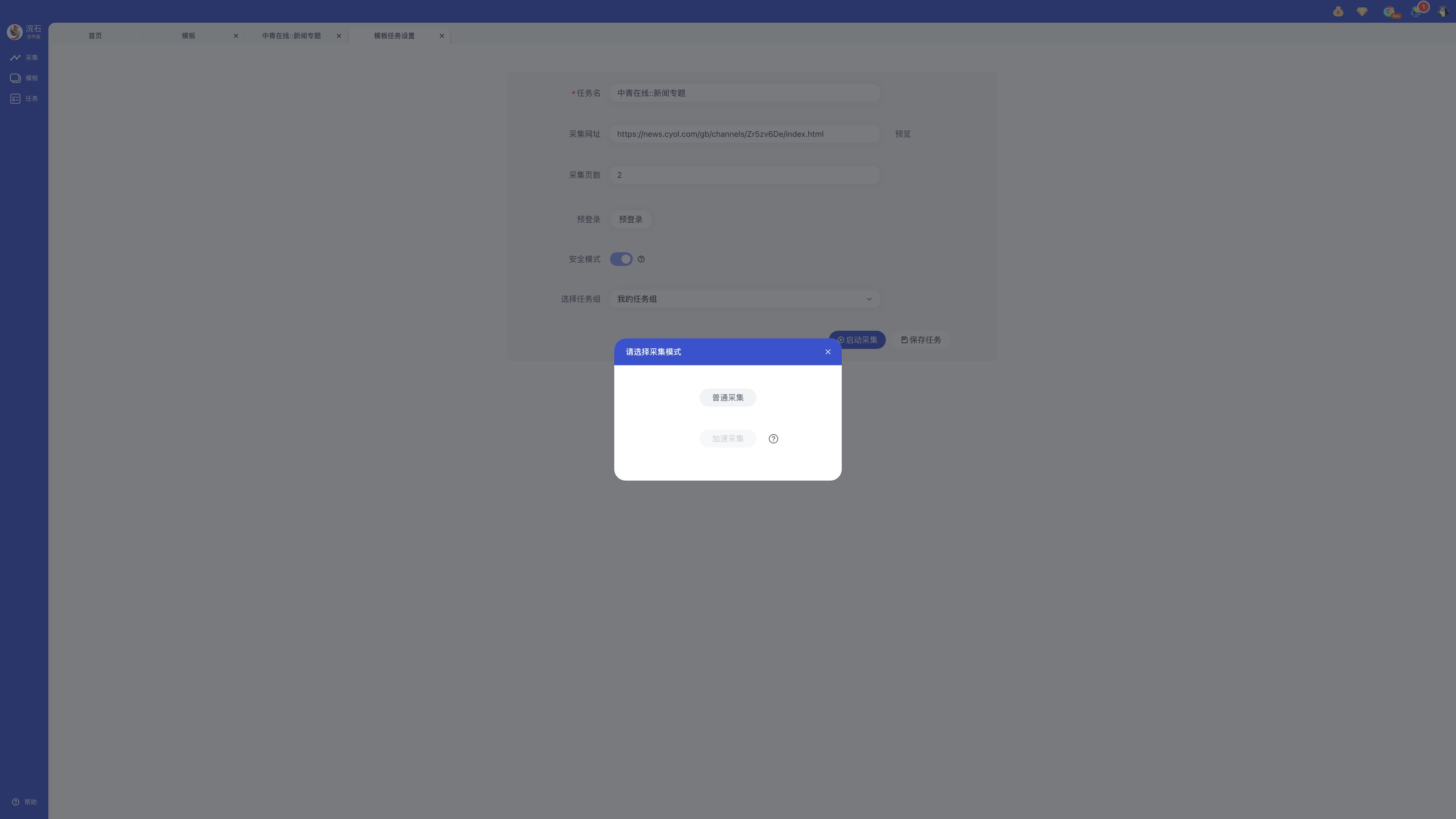
步骤四:采集完成后,可选择「导出数据」或「关闭」
API 采集提供了一种更直接、更可控的数据采集方式:您只需要填写接口地址(API URL),配置请求方式、参数、请求头与请求体,即可发送测试请求预览返回数据,并选择需要导出的字段,最终生成结构化数据文件用于分析与汇总。
API 采集适用于业务系统接口、内部平台接口、对接数据服务等场景,支持批量接口采集与字段提取配置,让“接口数据拿数”更高效、更稳定。
下面是 API 采集的示例:
步骤一:进入 API 采集向导
在采集模块中选择 API 采集,进入 API 采集页面。
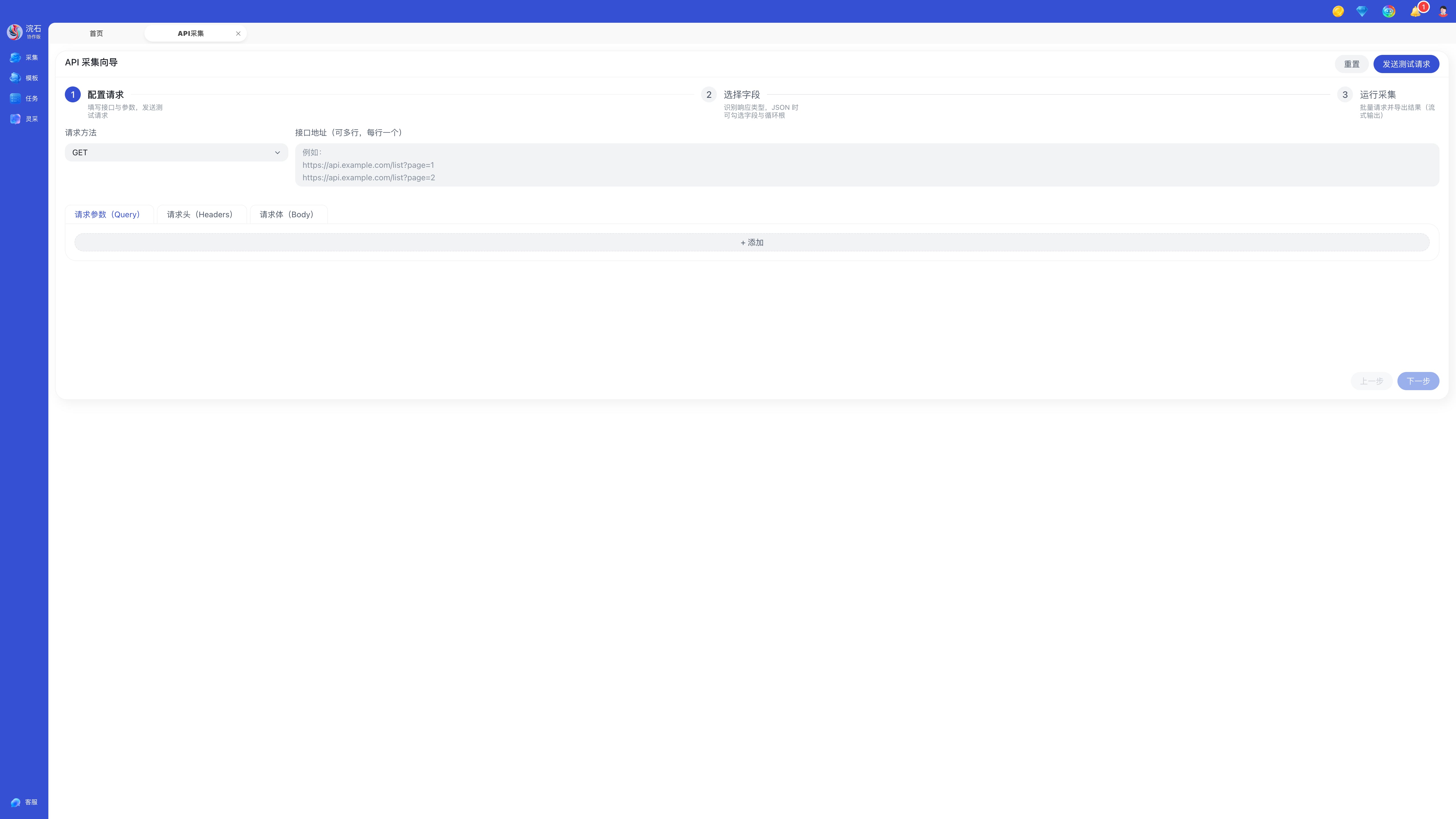
步骤二:配置请求
在配置请求页面,完成接口请求的基本配置:
1)选择请求方法
在左侧选择请求方式,例如:
GET:常用于查询数据
POST:常用于提交参数进行查询(如复杂筛选/分页/条件检索)
2)填写接口地址(可多行)
在输入框中粘贴 API 地址,例如:https://jsonplaceholder.typicode.com/posts。
当您需要批量采集多个接口时,可以按行输入多个地址,系统会逐行执行采集。
3)配置请求参数
在请求参数(Query) 中配置 URL 参数,例如:
page = 1
pageSize = 20
keyword = 张三
适用于 GET 查询、分页参数、过滤条件等场景。
4)配置请求头(Headers)
在请求头(Headers)中配置鉴权信息与必要头部,例如:
Authorization: Bearer xxxxxx
Content-Type: application/json
Cookie: ...(部分系统需要登录态)
5)配置请求体(Body)
当请求方式为 POST 时,可在 请求体(Body) 中填写参数,例如:
表单(Form):适用于简单键值对
JSON(Raw):适用于结构化条件查询
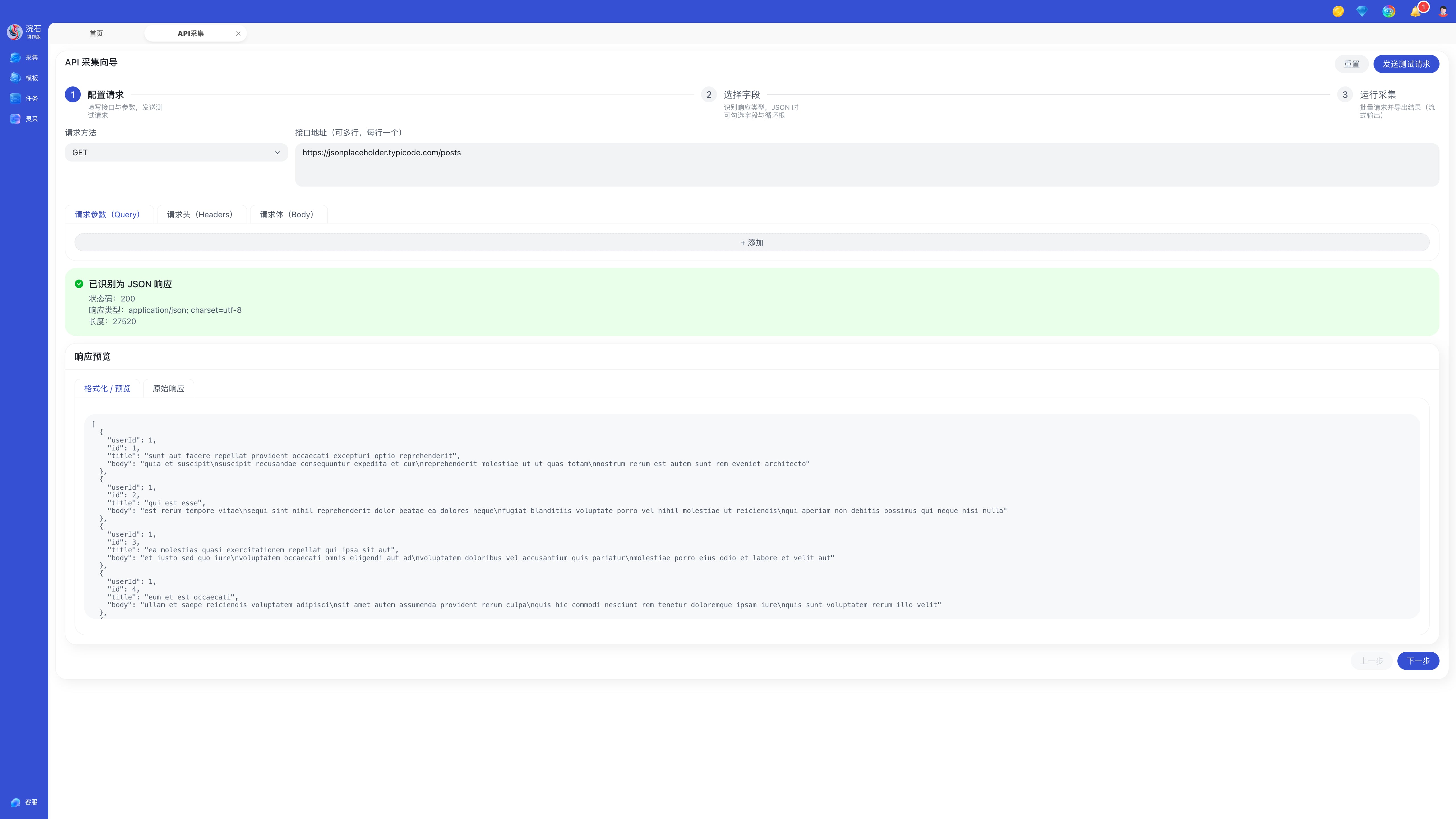
步骤三:发送测试请求
配置完成后,点击页面右上角发送测试请求。
测试请求成功后,系统会展示响应数据结构,帮助您确认:
- 接口是否可访问
- 参数是否生效
- 返回 JSON 的字段层级是否符合预期
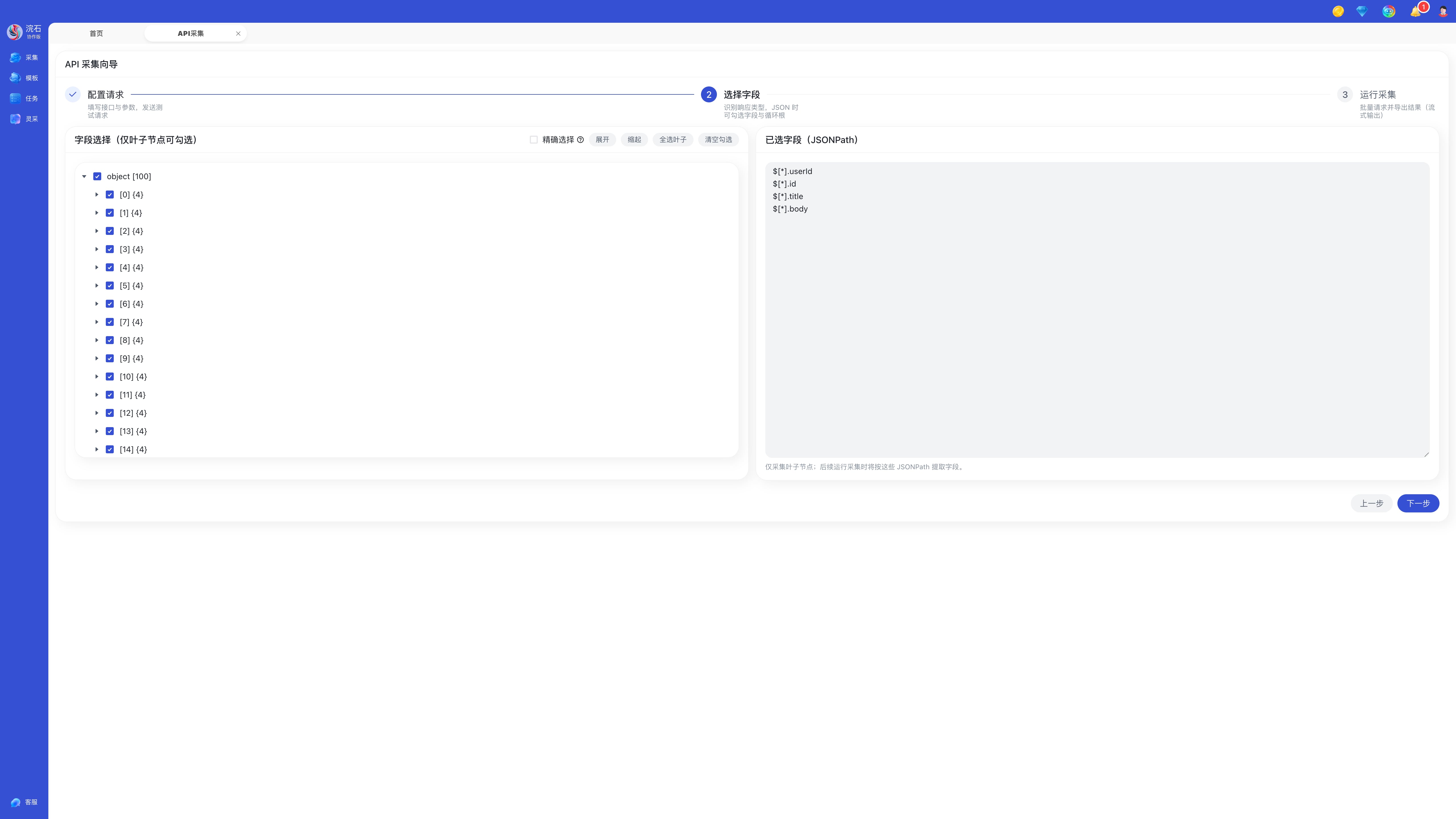
步骤四:选择字段
您可以在响应预览中选择需要导出的字段。
常见字段示例:
标题 / 名称(title / name)
时间(create_time / update_time)
来源(source)
链接(url)
列表明细(items / records / dataList)
选择完成后点击下一步。
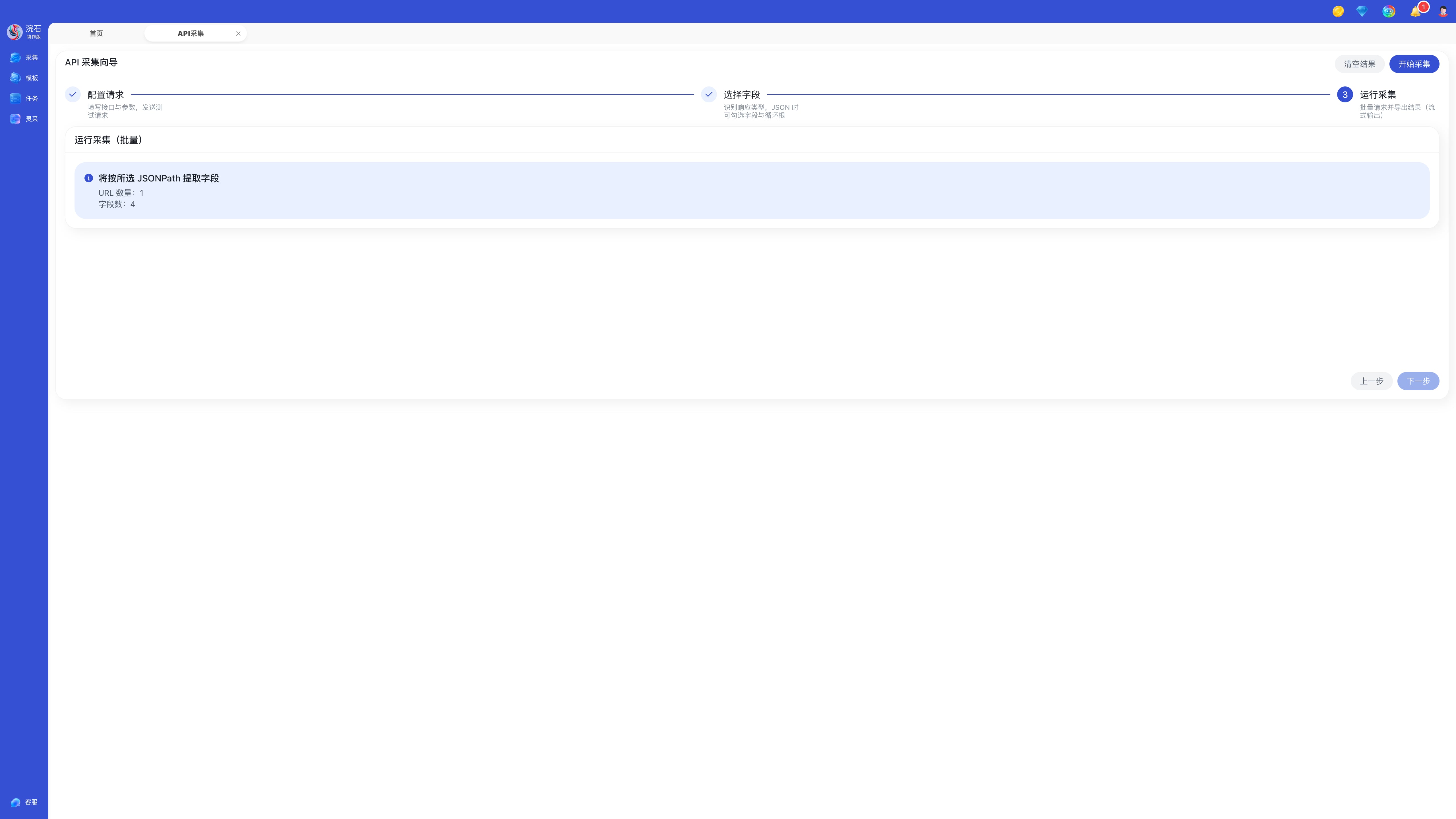
步骤五:运行采集
点击右上角开始采集执行采集任务。
采集完成后,您可以在任务模块查看采集结果与历史记录,对结果进行后续分析处理。
JSON 采集提供了一种面向接口数据的结构化采集方式。您只需要输入 JSON 地址(支持多行),配置请求方式、请求头与请求体,即可预览返回的 JSON 数据结构,并通过 JSONPath 提取所需字段,快速生成结构化结果用于导出与分析。
同时,JSON 采集支持页面注水解析:当目标数据需要依赖页面运行环境才能获取(例如页面加载时的 fetch/XHR 数据请求),系统可尝试从页面运行时捕获数据并进行解析增强,提升对复杂接口与非标准响应的采集效果。
步骤一:进入 JSON 采集页面
在采集模块中选择 JSON 采集,进入 JSON 采集配置页面。
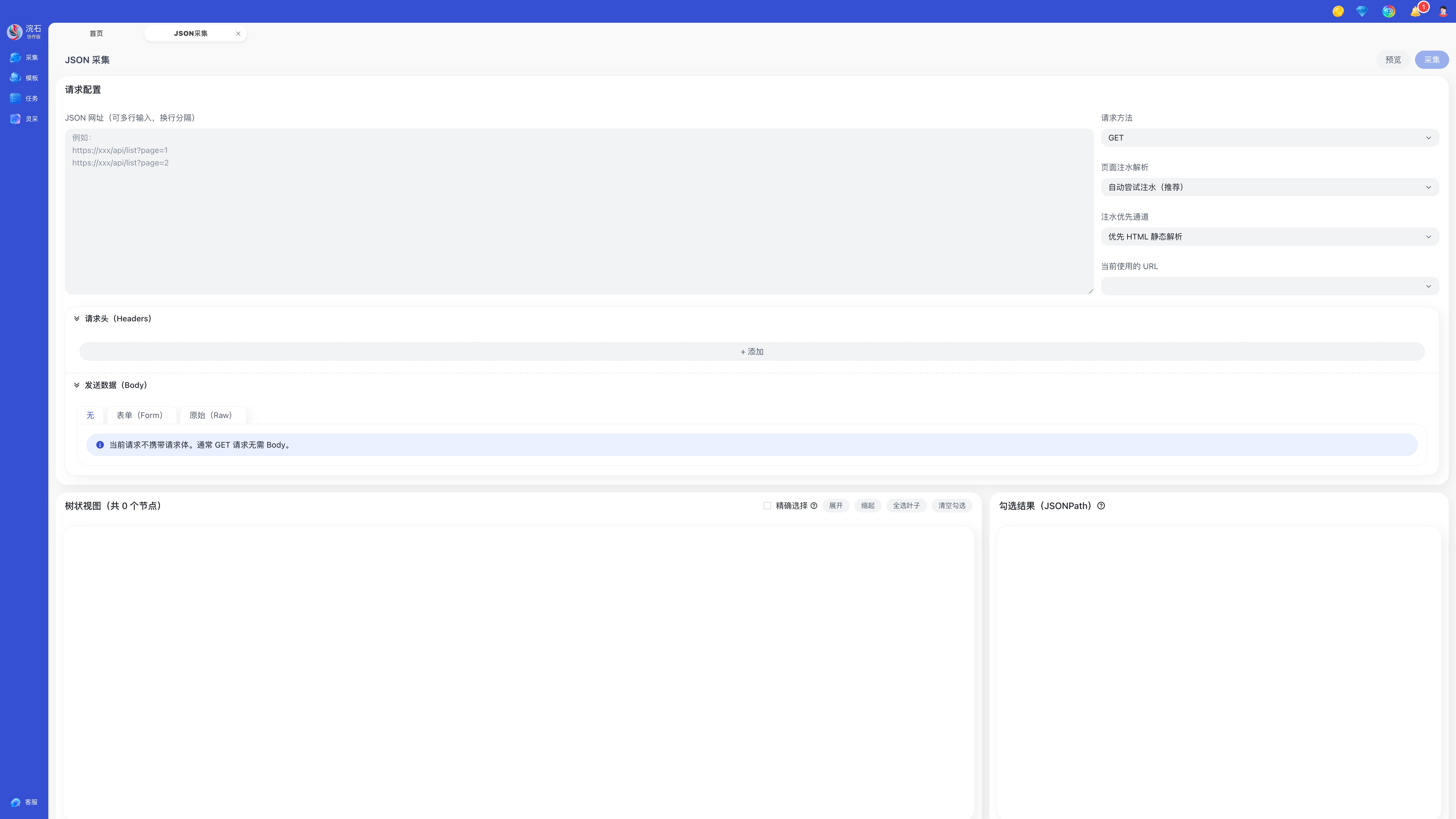
步骤二:填写 JSON 网址
在输入框中粘贴目标地址,例如:https://vercel.com/templates。
步骤三:配置请求方式与注水解析
在右侧配置区完成以下设置:
1)请求方法
选择请求方式,例如:
GET:常用于直接获取列表/详情数据
POST:常用于提交查询条件后返回结果
2)页面注水解析
支持开启“自动尝试注水(推荐)”。当系统检测到页面运行时数据请求时,将尝试捕获并解析页面注水数据,以便更稳定地获取结构化结果。
3)注水优先通道
可选择优先解析通道(如“优先 HTML 静态解析”),用于增强对非标准响应的处理能力。
步骤四:配置请求头(Headers)
当接口需要鉴权或特殊头部时,可在“请求头(Headers)”中添加,例如:
Authorization: Bearer xxxxxx
Content-Type: application/json
Cookie: ...(如接口依赖登录态)
步骤五:配置请求体(Body)
当请求方法为 POST 时,可在“发送数据(Body)”中配置请求体:
表单(Form):适用于简单键值对
原始(Raw):适用于 JSON/文本/XML 等格式
步骤六:预览数据结构与配置 JSONPath
点击右上角预览后,系统将展示返回的 JSON 数据结构:
左侧为树状视图:用于查看字段层级与数组结构;
右侧为勾选结果(JSONPath):用于提取所需字段与配置输出规则。
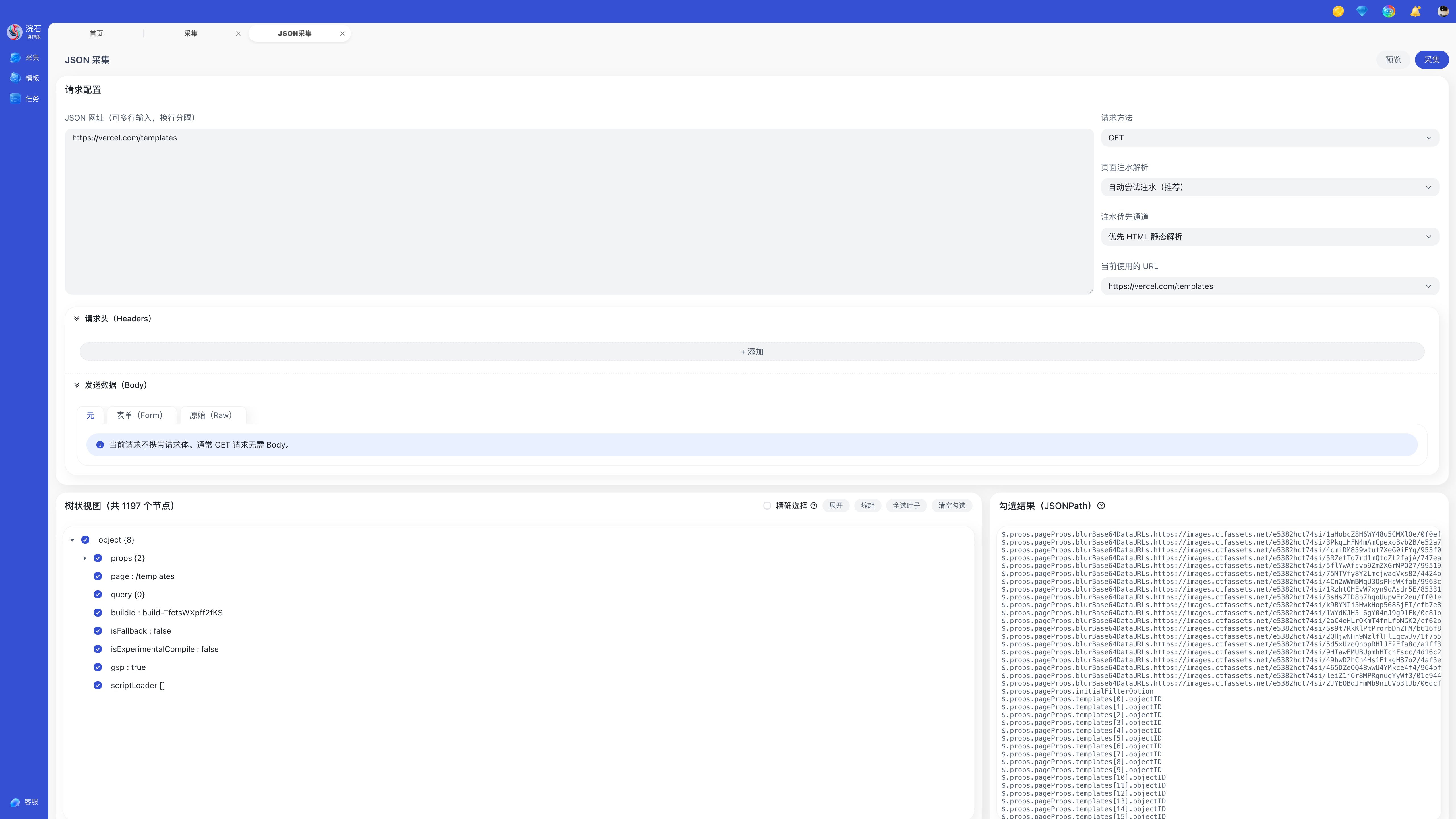
步骤七:运行采集
点击右上角开始采集执行采集任务。
采集完成后,您可以在任务模块查看采集结果与历史记录,对结果进行后续分析处理。
浣石采集器提供灵活多样的采集任务设置,满足您最苛刻的数据采集需求,包含了定时采集,强化采集,数据导出与智能分析等功能。
可按您的喜好调整卡片/表格视图显示
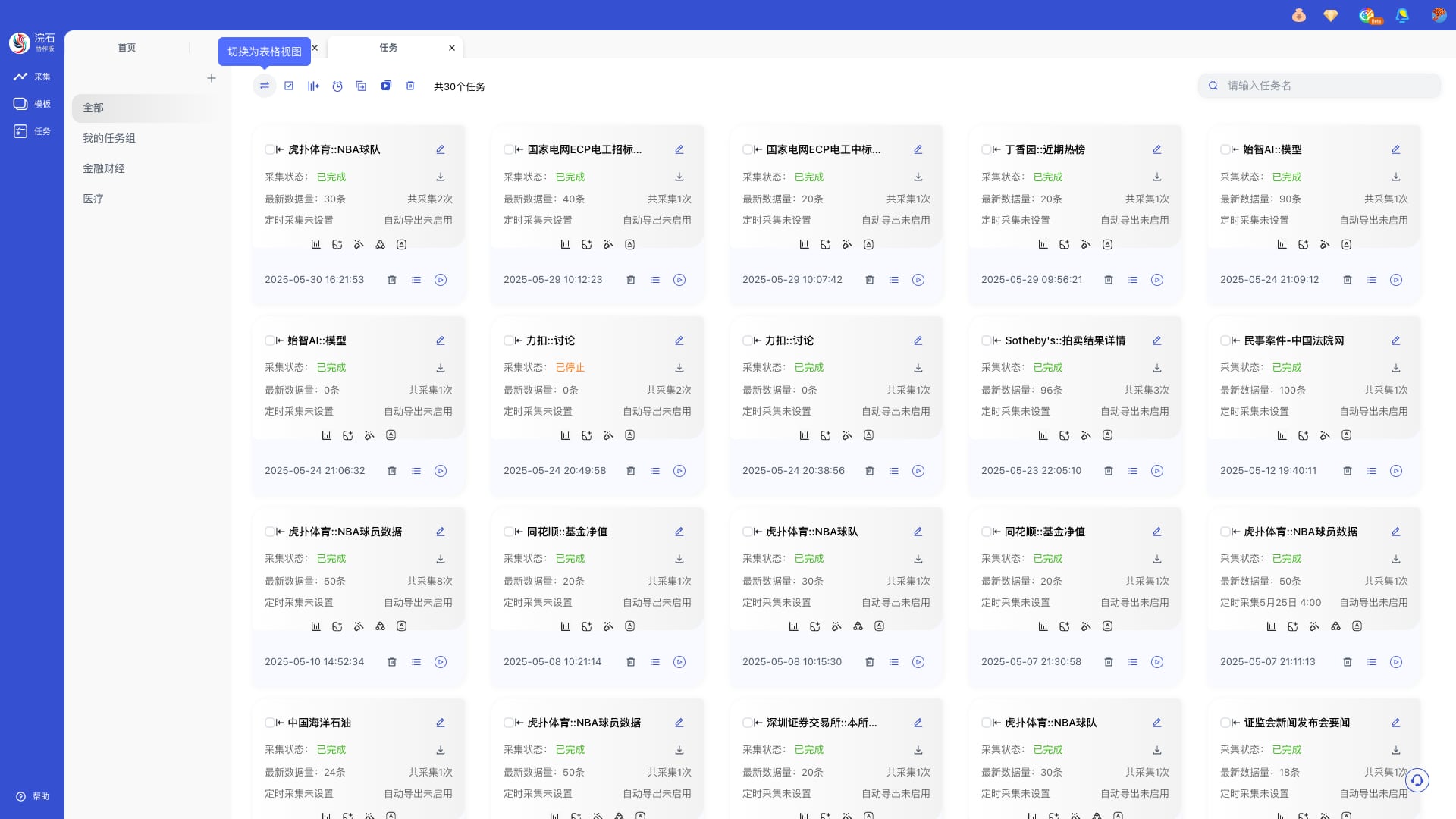
a. 采集任务设置,可对任务进行常规、强化采集、AI数据处理操作
b. 启动,您可以直接在「任务」中采集保存的任务
c. 预览数据,点击「查看数据」可预览采集到的数据
d. 操作,点击按钮导出文件保存至本地,右击可选择更多的导出数据保存类型
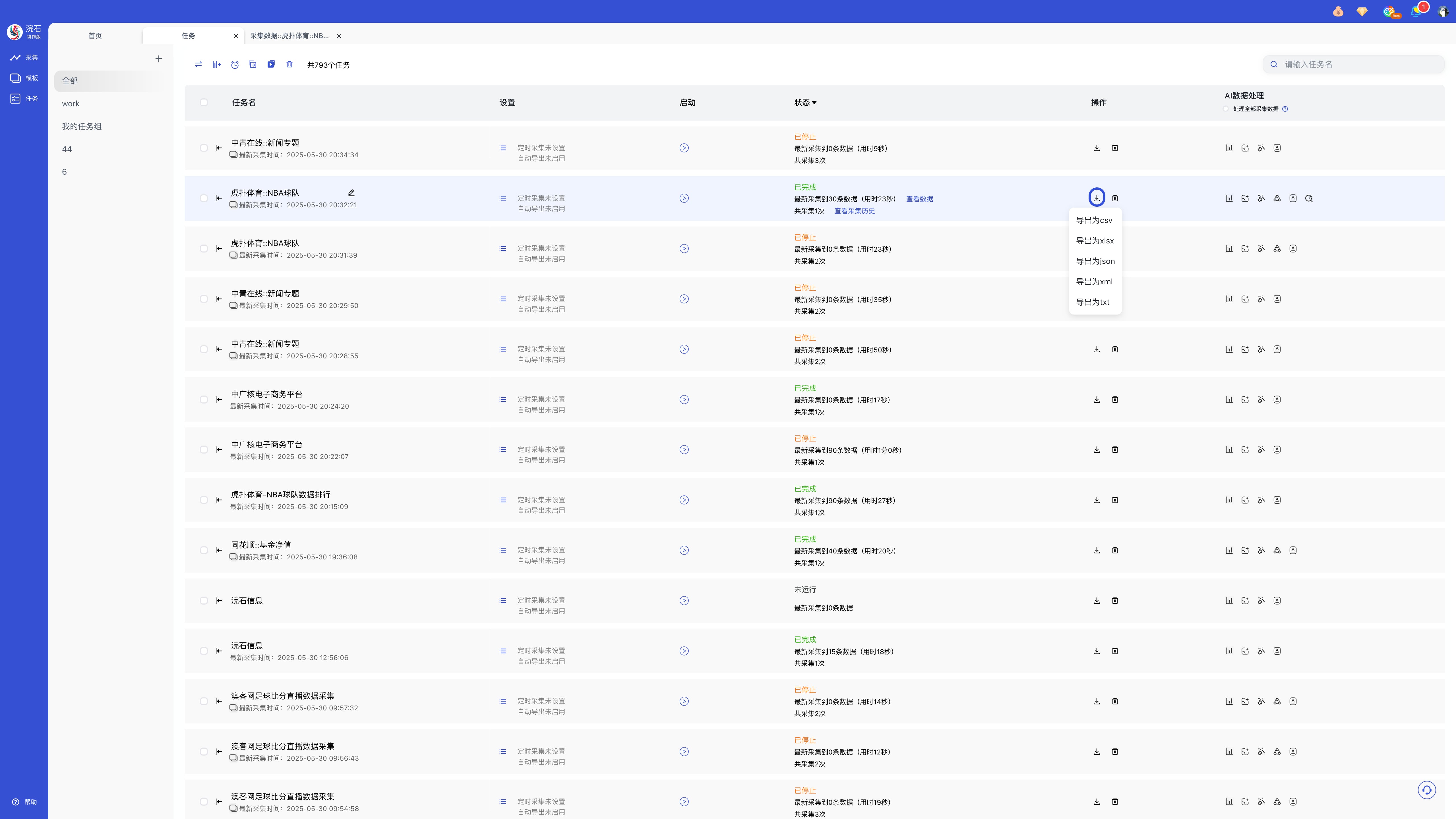
特别提醒:可在「采集任务设置」里设置文件导出路径
e. AI数据处理
您可以对采集完成的数据进行数据处理,浣小石支持「数据总结」、「仪表盘」、「思维导图」、「知识图谱」、「数据清洗」、「数据分析」、「数据挖掘」、「数据洞察」、「数据可视化」、「分析报告」、「深度搜索」等多种多样的处理功能,帮助您更高效地、更专业地分析、呈现、分享和利用各种价值信息。
部分任务提供「高级定制处理工具」,对采集数据实现更加独特高级的处理
特别提醒:AI数据处理默认处理最新任务的采集数据,可选择处理所有任务采集数据。
浣小石为您提供全程智能服务,从互联网数据采集到清洗、分析、挖掘、洞察与可视化,以58种浣小石触发方式,支持生成仪表盘、数据总结、思维导图、知识图谱、分析报告、深度搜索,并提供持续增加的高级定制处理工具,助力您的数据处理更精准更快捷。
在输入框内输入您的需求或问题,浣小石将迅速响应,同时,提供实用的辅助工具:
「深度思索」:深入智能分析您的问题或需求
「联网搜索」:实时联网获取最新的网络资源和信息
「上传文件」:上传本地文件供浣小石分析处理
「数据问答」:您可以围绕任务采集到的数据或已上传的数据文件,与浣小石展开多轮对话分析,例如进行数据总结、排序对比、结构解读或结果查看,帮助更直观地理解数据内容。
特别提醒
我们正持续优化浣小石的功能,不断提升其对各类数据的处理能力。处理不同类型的数据时,系统的表现可能会有所不同,部分复杂或特殊格式的数据可能需要更多的处理时间或调整。若代码解释器运行时出现报错,属于正常现象,系统具备自动纠错功能,会及时尝试修复错误并继续执行任务。我们正在持续改进,以提升用户体验和处理能力,感谢您的理解与支持!